Last week, I headed out to Boston to attend the second-ever TechSEO Boost, the only conference 100% dedicated to my favorite topic ever: technical SEO. This year’s theme focused on advanced and bleeding-edge topics including information retrieval and machine learning to service workers and computer programming basics.
You can watch the full live stream and access all the 2018 recordings here, but here are some takeaways I gathered from my favorite sessions:
The Statelessness of Technical SEO
Mike King surveyed 300 people asking them what they thought the definition of technical SEO is. He found that there is no clear consensus of what technical SEO actually is. Some survey answers were silly and answered “lie and bill” or “technical SEO is technical” where others defined it as simply “making sites indexed” and my personal favorite, “being curious.”
The main reason why technical SEO is stateless is that the SEO themselves do not do most technical SEO tasks. As most technical tasks are performed by non-SEOs, it is the function of the state of other capabilities. SEO is considered a meta-industry (pun intended) similar to the role a product manager plays in an agile framework. Technical SEO specifically is about scalability, extreme attention-to-detail, and advanced cross-functional understanding.
Mike believes the SEO industry desperately needs a governing body or standards similar to how HTML has W3. He’s already been working on developing a draft of those standards here.
Implementing Hreflang on Legacy Tech Stacks Using Service Workers, Does it Work?
The short answer is yes! A service worker is defined as a programmable proxy that sits between the server and the website. The winner of the TechSEO Boost research study competition bypassed legacy tech stacks and severe technical barriers.
Traditional Implementation Methods for Hreflang
- HTML <head> — most common method
- HTTP header
- XML sitemap
Non-traditional Implementation Alternatives for Hreflang
- Custom tags through a tag manager like GTM or DTM
- Service workers via a Content Delivery Network (CDN)
Option #5 was just proved to be successful through a recent experiment by SALT.agency that bypassed development using Cloudflare workers. Results of the experiment were observed within a week, and there was no noticeable impact on page speed. Service workers could theoretically be used for more than just hreflang – think canonical, redirects, server headers, and even content modification like schema markup.
Just Enough to be Dangerous: Programming Basics for SEO

TechSEO Boost’s founder, Paul Shapiro, challenged everyone to think of computer programming like creating formulas in Excel to execute a task or function. Focus less on learning on a particular programming language, like Visual Basic, JavaScript, or Python, and more on learning the logic that leads to transferrable knowledge.
Commonly Used Programming Variables
- Integer – a number without a decimal point
- Boolean – a true or false value
- String – text
- Array – a list of values
In my own experience, just having a basic understanding the different variables is very helpful for problem-solving issues with JSON-LD structured data.
On multiple occasions, my schema.org markup on a particular page will appear to be validated in the Structured Data Testing Tool but will not result in a rich snippet or result. When this happens, sometimes the culprit is an error in the JSON-LD like a missing quotation mark.
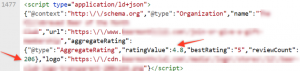
For example, one of my client’s aggregateRating schema markup for a product detail page failed to include a required offer property contained within straight quotation marks. The property should have been interpreted within the JSON-LD as an integer value but instead was considered a string. Illustrated below, you can see that reviewCount is seen as a string instead of an integer. Interestingly enough, the Structured Data Testing Tool didn’t report back any errors, but no rich result was earned until quotation marks were added back.
Machine Learning
Machine learning (ML), a subset of artificial intelligence (AI), is basically the ability to learn without explicitly being programmed by combining statistics and programming. Machine learning “learns” with either supervised or unsupervised learning. It needs training datasets that feed into the ML algorithms which are used to create the model. Loss function measures how off you are from the most accurate answer. ML is predicted to play a larger role in SEO and could be used at scale for creating automated metadata, image captions, transposing podcasts, and much more.
Research Roundup: Success Strategies for Better Experiments & Tests
“Do research so we don’t have to wait for Google to tell us what to do.” – Russ Jones
SEO testing differs from CRO testing because you can’t split audiences like you can with a traditional A/B test. Testing for SEO helps to break away from typical “best practices,” which tend to focus on tactics instead of strategy. Do your own SEO experiments to debunk myths and take a pause from drinking the Google Kool-Aid of “truths”.
SEO, WPO, SPA, AMP, PWA and Other Acronyms: Performance that Matters
“Use Chrome Dev Tools – it makes you look busy!” 😂 – Sean Malseed
When it comes to site performance and speed, there is no metric to rule them all. Lighthouse metrics may not be used that much now, but expect them to be in the future. SPOF stands for Single Point of Failure. It’s defined in web performance as a third party resource that fails, causing all subsequent resources to fail. It’s essentially a domino effect which can easily be prevented by defer and asynchronous loading. Async means that the resource loads in the background without interrupting other resources from loading.
Watching Googlebot Watching You: Optimizing with Server Logs
“SEO is the bridge between marketing and development.” – Jamie Alberico
Log file analysis has increased in popularity, especially since Google told us to check them to see if our sites had switched to mobile-first indexing. The idea was that if you had more server requests from Googlebot mobile than desktop, then your site had already been moved to mobile-first. Jamie Alberico explained that server logs are just like a server’s diary. They can be housed in a variety of places within the tech stack like a bot manager, a CDN, load balancer, or the server itself. Each line in the raw log files describes the server request recorded. Bot validation is essential for filtering out spoofed bots and can be performed automatically or manually via a script.
How to Get Access to Server Logs
- Ask the developer if there is a log management platform already in place
- Request that no Personally Identifiable Information (PII) is displayed
Whenever I get the opportunity, I personally use Screaming Frog’s Log File Analyser to review server requests for large enterprise sites. It’s helped me tremendously with identifying aggressive bot behavior (looking at you, Bingbot), crawling issues, and determining URL importance.
My 2¢
Overall, the 2018 TechSEO Boost conference was excellent and all the speakers were true technical SEO nerds. Although technical SEO tasks are typically performed by non-SEOs, I believe it is a required skill set that every SEO must practice. It will only become more important as search engines evolve and advance. With more inclusion and buy-in to integrate SEO than ever before between SEO and developers, the future is bright!
Join the #TechSEOBoost discussion on Twitter.