
This blog is a summary of the antifragile sw movement. There is lots of links. Loosely, Antifragile is the property of thriving through volatility and surprise. There is an antifragile sw manifesto, but note also that this goes beyond robust/resilient.
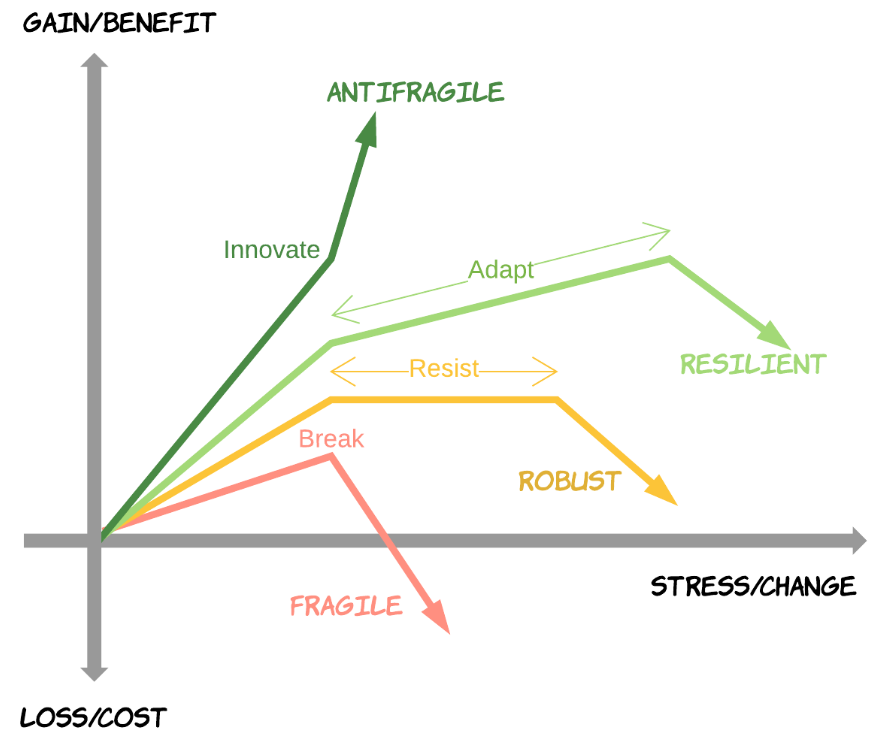
Bilgrin Ibryam’s picture of Antifragile Software.
As part of a Digital Transformation, here are six things to think about.
1. Adaptive Failure Injection
Hormesis is the acceptance of a little trouble to gain protection from bigger trouble. We use fault injection to improve testing coverage by adding some trouble. Fault injection alone is not antifragile. But, if the system also learns from the problems, then it becomes antifragile. Likewise, look at Simulated Fault Injection (SFI) and Software Implemented Fault Injection (SWIFI).
IEEE Xplore listed many fault injection tools. Here is a survey of techniques. Further, fault injection can be hw or sw and can occur anywhere in the dev cycle. At compile time, Fault Injection Description Language (FIDL) allows compiler based injection tools to be extended with new failure modes. And, Generic Object Oriented Fault Injection (GOOFI) is an scholarly look at layering tools for pre-runtime.
2. Automatic Bug Detection and Repair
Automatic bug-fixing repairs sw without a human programmer. A group is dedicated to this. Automatic bug repair is antifragile because advances therein directly improves the sw.

Folks at MIT have researched how to import checks from other applications (CodePhage) and perform automatic sw patches (Genesis). Note that, Semantic Aware Model Checking (SAMC) can be used for bug discovery. Claire Le Goues, in FTFY, explains research advances in automatic bug repair and GenProg is a general method for doing this on legacy systems.
3. Failure As A Service
The term may not stick, but Failure-as-a-Service (FaaS) allows cloud services to perform failure drills. Gremlin is said to be a FaaS and Daniel Bryant talks about Netflix failure service with failure injection testing (FIT).
As a result, FaaS is antifragile because it looks at failure as a good thing.
4. Autoscaling and Microservices
Software with autoscaling/microservices, and feedback monitoring, is antifragile because there is gain from increased duress. For example, AWS scaling of EC2 instances at infrastructure level and OpenShift scaling of app containers. Russ Miles wrote a book on creating antifragile sw with microservices. And, here are some Perficient articles on autoscaling with IBM WebSphere and MQ and IIBA HQ, Oracle WebCenter, and Elastic Beanstalk.
5. Antifragile Software Design
Russ Miles says we “attempt to deliver while being prepared for the unknown.” Vikas Singh has some designs for antifragile sw and suggests “high cohesion and loose coupling” and “while putting any new code in production, make it unpluggable in case things go wrong.”
Genetic Programming (GP) is designs that are expected to evolve. There is a group dedicated to this. Consider open source as an antifragile approach and well-aged platforms because, tech mortality decreases with time (Lindy Effect). Use principles of chaos engineering to address uncertainty. And, there is work on Lineage Driven Failure Injection (LDFI) to study fault tolerance of systems.
6. An Antifragile Culture
Finally, to produce more antifragile sw, the dev process and culture should itself be more antifragile. The org is important because sw tends to reflect the culture in which it was created. Rich Armstrong describes a process with a culture of FaaS, holacracy, and servant leadership. Bilgrin Ibryam states antifragility requires the right org and team structure.
So, antifragile includes continuous deployment and DevOps. Werner Vogel, CTO at Amazon, talks about the scaling, continuous deployment, and a workplace of the future that embraces errors. He says “Today’s digital business models require smaller, frequent releases to reduce risk.”
As a result, the sw of the future will have a rock-star team of bug writers!