
Perficient is exhibiting and presenting this week at KScope17 in San Antonio, TX. I delivered my presentation yesterday on modeling complex data security in Oracle BI. Here is the abstract for my presentation:
Learn how to build a position based security model to enable a position can view all it’s direct reports’ marketing/sales performance; learn how to build team based security model to enable a manager/supervisor to view it’s team’s performance on leads/opportunities; learn how to build org hierarchy based security model to view restricted data by organization; learn how to use views to optimize the data security performance in OBIEE; learn how to configure the data security for the reports.
I went through a very typical use case that marketing organizations use to secure analytics reports of who gets to see what.
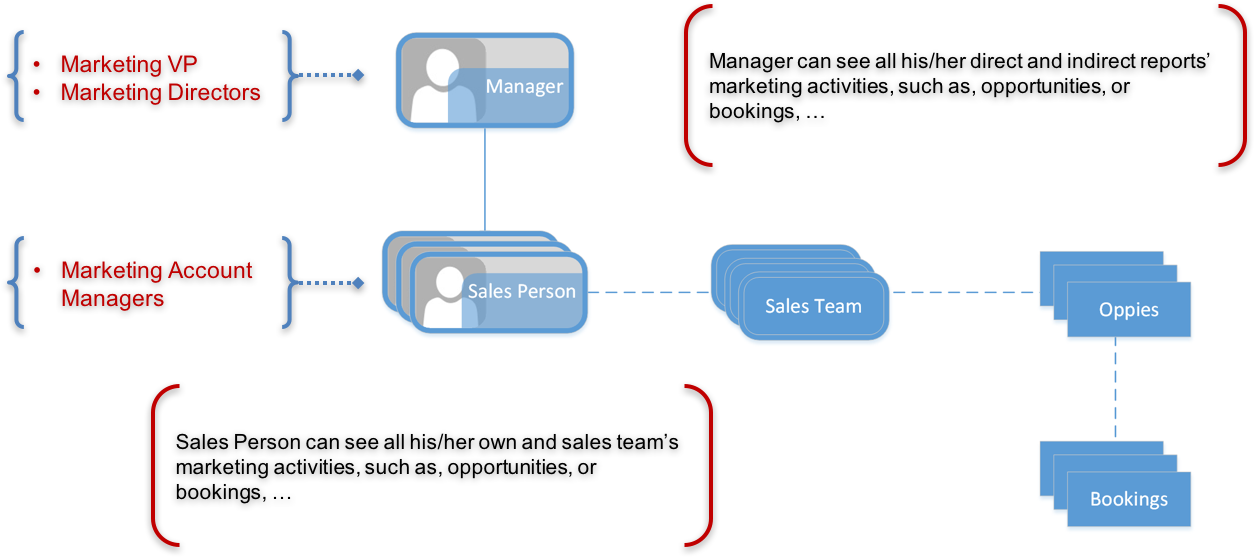
The typical challenge for such data security requirements is how we can model the data security to apply the m:m relationship to Star schemas where is typical of m:1 or 1:m relationship. The ERD for the use case looks like this:

Guide to Oracle Cloud: 5 Steps to Ensure a Successful Move to the Cloud
Explore key considerations, integrating the cloud with legacy applications and challenges of current cloud implementations.
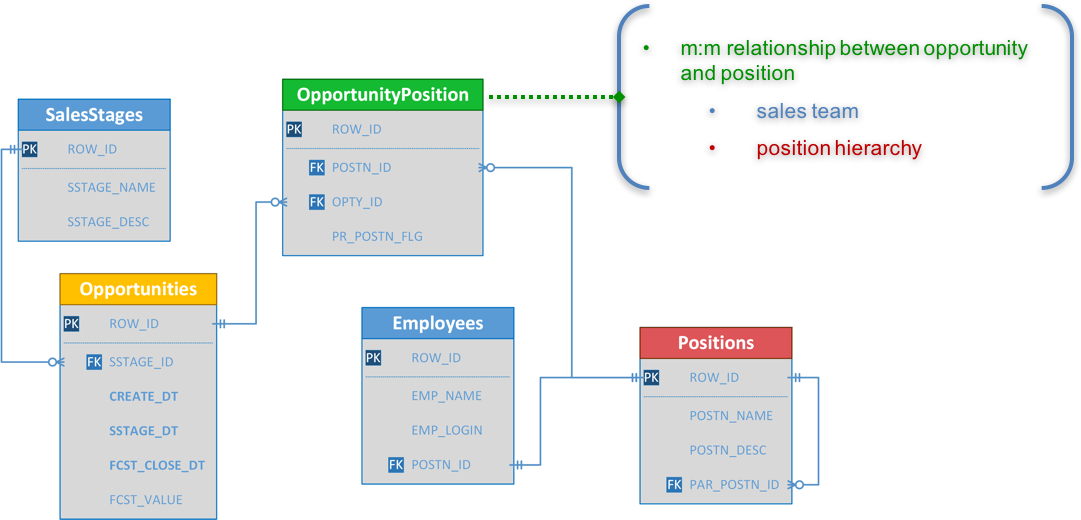
And the two Stars used for my presentation look like this:
|
|

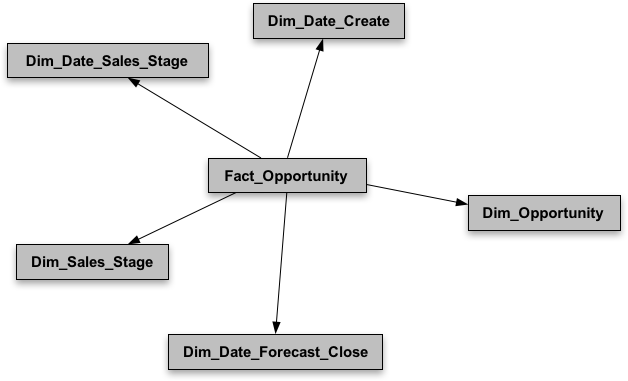
Applying salesperson and position hierarchy data filters for the Opportunity Team fact appears to be very straightforward; but when it comes to the Opportunity fact, it becomes a challenge. In my presentation, I went through four different data security approaches in Oracle BI, and their pros and cons.
- Dimension Data Filter
Dimensions can be directly applied to fact table as data filters. It’s typically used in where dimensions for data filtering are available and supported in the dimensional model. For example, such dimension data filters can be applied to the Opportunity Team fact. - Reverse Star Schema
Dimensions required for data filtering are not directly available in its own Star schema, but can be indirectly available through another Star schema via a common dimension. For example, such dimensions resulted from reverse star schema through the Opportunity dimension can be applied to the Opportunity fact. Since the reverse star schema is a logical implementation, it can be applied to the Opportunity Team fact as well. - Row-wise Session Variable
While reserve star schema might help to bring in the additional dimensions for data filters, but it might also have a performance problem for a large data volume because of its m:m cartesian join in the actual database query. The performance issue can be alleviated by using session variables defined as row-wise initialization to pre-filter the data elements that are visible to the logged in user and used in the security data filters. This approach can be applied to both Opportunity Team and Opportunity facts. - Opaque View
Instead of using session variables defined as row-wise initialization, we can create opaque views to pre-filter the data elements that are visible to the logged in user. Since views work the same as table, they can be used to model the data security in the data model level. Opaque views will always result in a unique list of data elements so that they can be modeled as dimensions and directly joined to the fact, or snow-flake the dimension, and used for security data filters.
As far as a best practice, I would suggest to address the data security in the data model level using the opaque view approach, to model the data security correctly in the first place and have flexibility to adapt any new data security or change in the future.