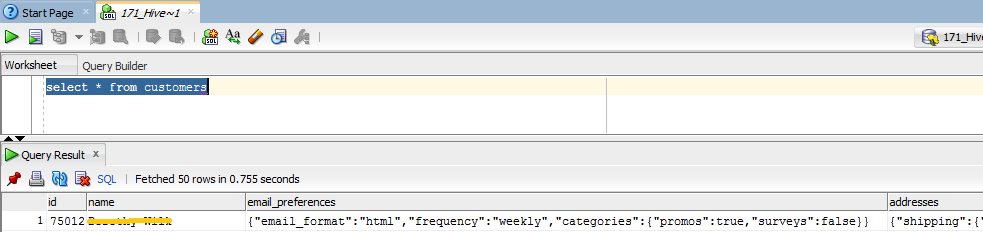
In my previous post, I introduced a HiveServer2 based approach to query data in Java code. If we don’t have to write any additional code, we could leverage a Database tool to do the manipulation. As we know, Oracle SQL Developer is a free tool that can be used for different kinds of databases by installing third party JDBC drivers. This diagram simply depicts the process of SQL Developer connecting with Hive database in a distributed cluster.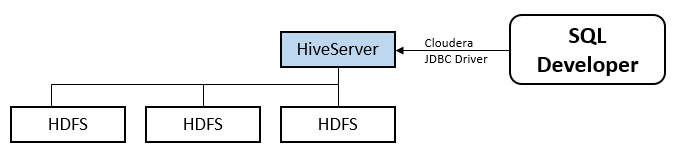
To connect with the Hive Data warehouse, please use the following steps to perform your configuration in the Windows OS.
Prerequisite
You have installed Oracle SQL Developer version 4.0.3 or later;
You have Hive cluster nodes which could be Hortonworks or Cloudera data platform. In my case, I used the HDP 2.5;
You have installed JDK 1.8;
Step 1

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
Download and Copy the Jars to SQL Developer folder. Cloudera has developed the related drivers and you can find them on its download page. After you extract the zip files, you will see a quick guide (pdf) and a bunch of .jar files. Copy them into one of the SQL developer installed folder like …\sqldeveloper\jlib\HiveJDBC\.
Step 2
Open your SQL Developer, go to Tools -> Window, select the database section and Third Party JDBC Drivers, iteratively add the entries to select all 15 jar files as in the below screenshot. Then save this setting.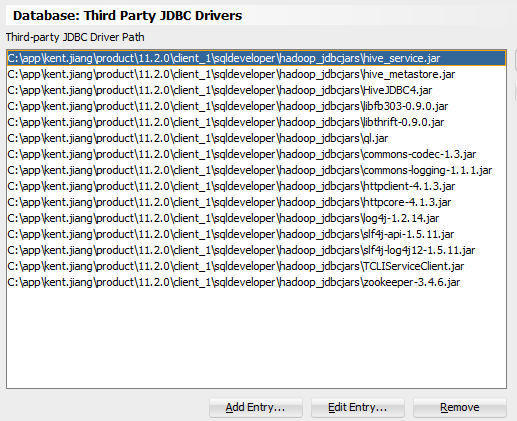
Restart your SQL developer, and create a new connection, in the dialog you should see a new tab called Hive.
Tips: if you did not see the Hive tab, please go back to perform the above steps again. You will need to remove all added jars, and just add 3 jars starting with ‘Hive’ then save it. Restart SQL developer and create a connection to check. After you can see the Hive tab, then continue adding other jars.
Step 3
Create the Hive Connection and Configure Parameter. As stated in the Cloudera guide, there are 4 authentication methods:
- No Authentication
- Kerberos
- User Name
- User Name and Password
We will need to check out which type of authentication mechanism is set in the Hive server side. We can either go to the Ambari page which is the admin console for Horton rocks, or the open /etc/hive/hive-site.xml to check the property. Here is my case.

This indicates I am using the “user Name” method, so I need to configure my connection as below.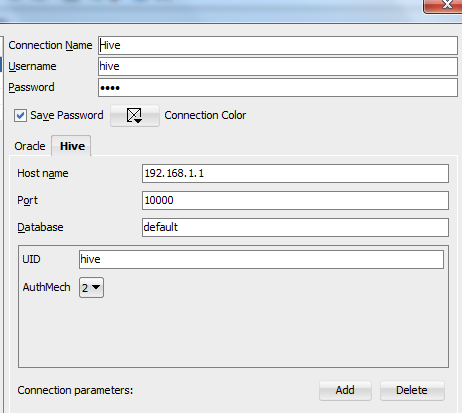
Now you’re able to manipulate the Hive big data table!
Create a table and Insert data. Now you should be able to connect to Hive DB and run your DML scripts. You can create a table with the HiveQL language and export some data from Oracle tables via Oracle connection, and then insert to the Hive table. That is a convenient way to get your Oracle table migrated to Hive.