
Many people assume that Google leverages all of its vast information resources in every way possible. For example, the great majority of people who think about it probably assume that Google uses their Chrome browser as a data source, and in particular, that they use it to discover new URLs for crawling.
We decided to put that to the test.
Brief Methodology Note
The test methodology was pretty simple. In principle, all we needed to do was set up a couple of pages that Google didn’t know about, have a bunch of people visit those pages from a Chrome browser, and then wait and see if Googlebot came to visit it. In practice, there was a bit more discipline involved in the process, so here is what we did:
- Created four brand new articles as web pages. We used two of these as test pages, and two of them as control pages.
- Uploaded them to a website by direct FTP to a web server. By that, I mean we didn’t use any Content Management Systems (e.g. WordPress, Drupal, …) to upload them to make sure that something in that process didn’t make Google aware of the pages.
- Waited a week to make sure nothing went wrong, causing Googlebot to visit. During that week, we checked the site log files every day to make sure that no Google bot visits occurred.
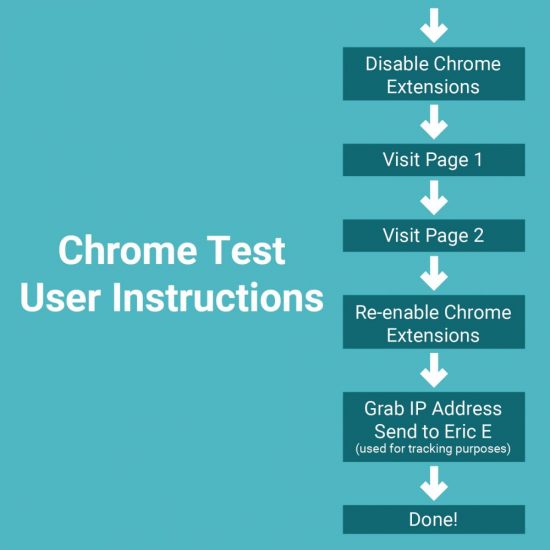
- Enlisted 27 people to follow this process:
- Open Chrome
- Go into settings and disable all their extensions
- Paste the URL of the first test page in their browser and then visit it
- Paste the URL of the second test page in their browser and then visit it
- Reenable their extensions after completing the steps above
- Grab their IP address and send it to me so I could verify who followed all the steps and who didn’t
- Checked the log files every single day until a week after the last user completed their steps

Note that the control pages were never visited by humans, and that’s what makes them controls. If something went wrong in the upload process, then they might get visited, but that never happened. No views of either control page ever occurred, either by humans or bots, so this confirmed that our upload process worked.
What do people believe about this?
In anticipation of this test, Rand Fishkin of Moz put out a poll on Twitter to see what people believed about whether Google uses Chrome data for this purpose. Here’s his result:
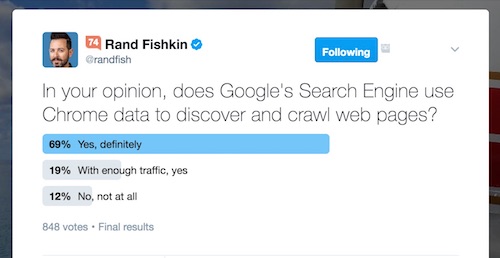
As you can see, a whopping 88% believe Google sniffs new URLs from Chrome data, and the majority of those are sure they definitely do it. Let’s see how that compares with the results of our test.
[Tweet “88% believe Google uses Chrome data to find new URLs. But do they? We found out! See”]
The Results
The results are pretty simple: Googlebot never came to visit either page in the test.
As it turns out, two people in the test did not actually disable their extensions, and this resulted in visits from Open Site Explorer (someone had the Mozbar installed and enabled) and Yandex (due to a different person, though I’m not clear on what extension they had installed and enabled).
Related: Does Google Use Google Analytics to Discover New URLs?
Summary
This is a remarkable result. Google has access to an enormous amount of data from Chrome, and it’s hard to believe that they don’t use it in some fashion.
However, bear in mind that this test was specific to testing if they used Chrome to discover new URLs. In an earlier test, we showed that Google does not use smartphone clipboards to discover new URLs either. My guess is that Google still is of the mindset that if there is no web-based link path to a page, it doesn’t have enough value to rank for anything anyway.
This does not mean that Google does not use Chrome data in other ways, such as to collect aggregate user behavior data, or other metrics. Google’s Paul Haahr confirmed that they do use CTR data as a quality control in highly controlled testing to measure search quality.
Note: He did NOT say that it was a live ranking factor, but more a way of validating that other ranking factors were doing their job well. That said, perhaps Chrome is a source of data in such testing. It could easily be made truly anonymous, and perhaps add a lot of insight into user satisfaction with search results.
In any event, this part of the conversation is all speculation, and for now, we’ve shown that Google does not appear to use simple Chrome visits to new web pages as a way to discover URLs for crawling.
Thanks to the IMEC Labs group for their assistance on this test, and to the IMEC board of Rand Fishkin, Mark Traphagen, Dan Petrovic, and Annie Cushing for their guidance. Please follow all of them and me, Eric Enge, for more info on IMEC tests in the future!
Want to keep learning? Check out all of our digital marketing research studies.
We have a CMS that pushes Product pages live before completion. They are 200 status, not complete Product pages, and are not the final URL. I.e. once complete the URL 301 redirects to a friendly URL. I forgot the exact reason, but people internally search for the non-complete URL on browsers. Google is finding and crawling these URLs daily according to our log files, but not indexing them (a site: search returns 0 results). An example of such a URL would be
http://www.example.com/product/-/4568756. Eventually it would 301 redirect to something like http://www.example.com/product/brand-product-name/4568756. I don’t know how else Google would find these pages: they aren’t linked to internally, no one externally should know they exist and link to them, yet Google crawls about 100 to 150 of them daily.
Thank you for the info,
I learn every day
It would be good to see these tests reproduced on a monthly basis to see if things have changed?
Hi Nick. We do repeat many of our tests where it makes sense, but since this is a belief that has persisted for years, a one time test probably suffices to lay it to rest, at least for a good while. It’s something Google has said they don’t do, and we’ve simply confirmed that. Of course, our methodology is all in the test report, and anyone would be welcome to reproduce the test on their own.
They said they didn’t read your emails either? I can’t believe that Google doesn’t use this data in one way or another
Actually, Google is very open that they do “read” your Gmail in order to serve you contextual ads and to perform personalized services such as events going automatically to your Google Calendar, and reservations showing up on your phone. I put “read” in quotes because no human actually looks at your emails; it’s all done by machines for those services. Also, as Eric said in his post, we are not making any claim about whether or not Google uses data from Chrome for anything else. Our test only checked on one very specific possible use.
Mark this case study is really weak. Instead you should create one epic webpage and share it on some Facebook close groups. And I bet Google will index those pages very fast based on popularity of that webpage.
I have seen many popular webpages index very fast with no links, no sitemap and no search console account.
Google main abstract is to crawl important webpages first, and they can’t simply rely on sitemap and links based crawler. There are lot’s of webpages out there which are popular and it should index very fast, and hence I think they may be have other type of crawler as well.
Hi,
Thanks for sharing your results.
So Googlebot didn’t show up but you do not say if those urls were indexed in Google SERPs. Did you checked that point?
Do the test urls contain enough quality content to be indexed?
I wonder if Chrome could replace the Googlebot as it has already all the data needed for indexation, and far more.
Hi Francois. No URL can get indexed for Google Search unless it is first crawled by the googlebot. That’s simply how Google Search works. And yes, the test pages contained well-written content, and were posted on a reputable site.
Goyllo, we respectfully disagree, as the test accomplished the thing it was designed to test: whether or not Google uses user behavior on its Chrome browser to discover new pages. We were not testing whether Google has other means (such as social media links) of discovering new pages, nor do we dispute that it does. In fact, in another test we demonstrated that just tweeting a link to a previously unrevealed page can cause googlebot to visit and crawl a page (no guarantee; it didn’t happen every time).
Furthermore, the pages were hosted on our site, which has established a very high crawl priority with Google. Normally, pages we haven’t intentionally hidden from Google get indexed within hours of their publication.
/facepalm
HiBob – I don’t have a clear answer for you, but they have to be discovering them somehow. There are many ways that this can happen. For example, if you visit a page using a browser that has a toolbar that calls the Google Plus API when it loads. We’ve seen them crawl URLs when pages are exposed that way. Just not with Chrome by itself (with no active toolbars).
Hi Michael – they may well be using the data in some other way, but what we show is that they don’t use it for discovering URLs to crawl.
I have to disagree with the conclusions here – I’ve seen Google index sites on staging with no links pointing to them whatsoever and the site still shows up in in index and the only way Google could know that that page exists was if it discovered it via Chrome.
Of course, that was a while ago – it is possible that Google was using Chrome at one point, and simply stopped using it because it was getting a lot of noisy info.
Eric,
Thanks for the clarification and insight, I appreciate it!
Hi Jason – this is something we also tested 3 years ago, and we got the same results. Two other reasons pages may have been crawled, simply because you loaded them with a Chrome browser:
1. You had a toolbar running which included a Google Plus +1 count checker – we know this will spawn a crawl.
2. When you loaded the page, it had some other Google code on the page that ran, and Google used this for URL discovery.
What we did in our test is that we loaded pages that were simple HTML text files, with no Google code on them, and we made sure that everyone disabled all of their Google Add-in prior to loading the page.
What if Google’s threshold is 28 direct visits before they take notice and crawl?
Maybe 200, or 2000 would do it. I think you have proven that 27 direct visits don’t cause a crawl in a week. Maybe it happened on the 8th day….
Agreed, maybe there’s a threshold at 28, or 32, or 67, but I do think that those possibilities are a bit less remote. Maybe it’s 1000.
But consider this idea. Google doesn’t crawl things that don;t show some level of significance. A simple volume of vists, or social shares does not meet that test. If it did, ever cat or dog photo ever shared would be indexed, and prominent in the search results.
My belief is that they need other signals, such as links to decide to index something. If the content does not draw links, why index it? Lot of page views, or social shares could just be another cat pic.
Hi,
Thanks for sharing your results.
So Googlebot didn’t show up but you do not say if those urls were indexed in Google SERPs. Did you checked that point?
Do the test urls contain enough quality content to be indexed?
I wonder if Chrome could replace the Googlebot as it has already all the data needed for indexation, and far more.
thanks
Hi – AR, no, the pages are not indexed. We did check that. The pages were written as substantial pieces of content worth indexing.
This is just a rumors, google does not need to spy on your browser to discover new pages, its us who want google to push and craw out URL to get them ranked.
its myths cum fake news.
Regard
Jim Piccolo
In the past our website had a folder for a new version of the website that had a robots.txt to block all bots and it was crawled and went on google serps, in spite of the folder url never been submited to Google at all…
Thanks for being mythbusters wuth this article. I was also preaty sure they use it but after reading this, it’s totally making sens. Imagine the open door to google bombing if it does. Many bots, many chrome instense… many mistake
Jim, it’s unclear just what you think is a rumor, myth, or “fake news.” Many SEOs and search experts have speculated that Google was using Chrome data to discover new URLs, simply because Google could do that. Our test shows that it is highly unlikely that they are. That’s it.
The article is quite informative. Can’t find out how the google bot actually crawls the website. despite of sitemaps, robts.txt, all the pages are not indexed..can you suggest something??
You can learn what pages your site Google is crawling by looking into your log file. This is best using a tool called a log file analyzer (you can search on that to find some good ones).
As for other reasons you’re site is not completely indexed, the list pf possibilities is long. Google might see the content aas being “thin” (search on thin content to learn about that), or it may just not be attracting much attention from others on the web (e.g. it may have no high quality links to it), the Sitemaps file may have problems in it, it could be badly structured, or it couild one of many other potential problems. It’s hard to say without doing a detaled analysis of it.
Thanks Eric. I have been working on on-page optimization and have worked on majority of them. But yes, the challenge is to get good quality backlinks.
I’m glad Google doesn’t use Chrome to discover URLs, because I sometimes temporarily put private or draft documents onto a server for myself or others to fetch later by direct URL and forget to write a deny entry in robots.txt (and if you’re on a shared server you might not even have access to robots.txt). As long as said private documents don’t link to external sites that might give the game away by publishing their referral logs, I can be reasonably confident that they won’t get crawled as long as I can trust everybody who knows about them to refrain from linking to them. (Somebody could brute-force fetch every possible URL, but if they’re going to go that far then there’s not much hope anyway: yes I could put it behind a password, but what’s the difference between brute-forcing a URL and brute-forcing a password? Thankfully the private documents I’m talking about are not worth going THAT far for.)
The answer is yes. In fact, all browsers, extensions collect user data. Currently there is only one open source project declaring that they do not collect any user’s information. That is Tor Project. (As I know)
Yes, they collect data, but as our test showed, they don’t appear to crawl URLs that are discovered via Chrome.
yeh off course. Because google use cache and cookies. this why they collect ton of data from users.
i read the Rand Fishkin tweet and read all comment below them. i am agree with him.
Monjoli, read the study carefully. We are not denying that they have the ability to collect the data. That is not in question. The question is whether or not they use it for new URL discovery, and our test demonstrates that they do not.
Ok. i think they do.
I think if they did use it, they’d get a LOT of noise when you factor in dev sites, localhosts, session ids, cookie ids, and all the URLs that are normally blocked from the crawler. It would probably be a huge waste of resources to crawl them all. Besides, if they aren’t linked to on the web from anywhere, are they really important?
Completely agree.
In terms of crawling, this method is really good & useful for publishers. But they do with data, is it happening as per user policy?
They certainly use the Chrome data in a more aggregated fashion to gain insight on user behavior and the like, but it’s hard to know the spepcifics of what exactly they do with it.
A very interesting article, we have noted definitively in online reputation management that there is correlation between post click data in chorme and results in ORM SEO.
Are you able to share some specific data on that?
it’s a too informative post for me and I learns a lot from it………………….thanks for sharing it.
I think they already have billions of urls Crawled and they are more focused on arranging them instead of finding new one.
Ali indeed they do, but it’s not a matter of being more focused on old vs. new. They are constantly indexing a great many new URLs.
For a long time now they have had to prioritize what they index.
I think they already have billions of urls Crawled and they are more focused on arranging them instead of finding new ones.
Actually, it’s just as important for Google to be aware of and index new URLs as ever. Information is constantly changing.
I’m going to call BS on this “experiment”. I created a subfolder called foldername under a folder which already had an index.php. There’s no way Google could have known about the existence of this subfolder, other than from chrome. And right now I’m sitting here watching Google’s bots scan through every file and folder in that sub folder.
There are several things to watch for in your test:
1. Did the page have Google Analytics or Google Tag Manager on the pages you created?
2. How about any other Google functions, such as Google Plus one buttons or any other Google function calls? Any of these would invalidate the test.
3. Last, but not least, do you have any toolbars installed in your version of Chrome? For your test to be valid, it’s important that there are no toolbars installed, as some of them do make calls as the page is loaded that tips off Google as to the page’s existence (for example, the Moz bar makes calls to Google functions).
Hope that helps.