
The era of machine learning is upon us. It’s far more prevalent than you may be aware. See those movies that Netflix recommends you consider watching? That’s being decided by a machine learning algorithm. Did you notice when your search engine recognized that a face was present in a picture? Machine learning again. Love interacting using voice commands with Siri or the Google Assistant? Yup, machine learning one more time.
It’s been Google’s mission from the start “to organize the world’s information and make it universally accessible and useful.” It just might be the most daunting mission statement any company ever set for itself. To make matters worse, there will be 50 times as much data in 2020 as there was in 2010.
The Changing Face of Information Retrieval
But the mission is morphing. Historically, to get at that information, you would have to form a request for it, and you’d have to concoct specific language to help the search engine understand what you want. But now, companies like Google, Facebook, Microsoft, Amazon, and Apple are all vying to deliver it to you when you need it while allowing you to use your own language. In many cases they’ll even send it to you before you have even asked for it! They are are also looking to be able to answer questions that were previously not easily answered with, or without, computers.
The Google revolution was possible because of the ability of computers to rapidly index and access large amounts of data. (See How Google Search Works for more on how that happens.) But that only deals with the first part of Google’s mission (“organize the world’s information”). Getting to the second part of the mission (“make it universally accessible and useful”) is an even bigger challenge, and machine learning is at the heart of it.
Enter the Machine Learning Revolution
Machine learning is a class of algorithms that enable computers to learn how to handle certain tasks without being explicitly programmed in how to do them. In it’s simplest form, it’s used to solve problems that are hard to solve using conventional means, and at the high end the leaders of this space are using deep neural nets to try and mimic the way that the human brain works.
Perhaps the most famous example of the power of unsupervised machine learning to date is AlphaGo, a project of DeepMind (a subsidiary of Google’s parent company, Alphabet Inc.). AlphaGo was programmed to learn the ancient Chinese game Go, and to be able to play it at a championship level.
This was no simple task. Go has 10171 possible positions. How big is that number? Well, it’s estimated that there are 10100 atoms in the known universe.
It was beyond impossible to provide AlphaGo with explicit instructions covering every possible move, so given the rules of the game and some instructions and training on Go strategy, the algorithm had to learn through simulated playing, constantly improving its game. The result? In March 2016 AlphaGo beat the top human Go player in the world, four matches out of five.
Supervised and Unsupervised Machine Learning
Supervised learning is when the computer is given “training data”, and based on that training data, it’s expected to be able to learn how something works.
To illustrate, let’s start out with a simple learning problem that doesn’t require machine learning … yet. Say you have a set of data showing the average prices of homes compared to their size in square feet:
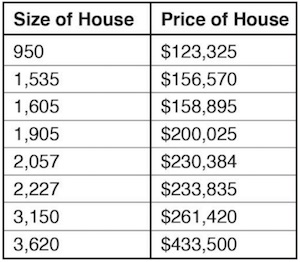
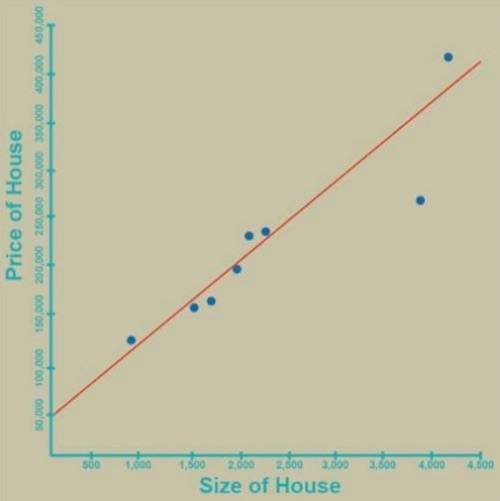
If you want to know the relationship between the size of a house and its price, the solution is easy. Just plot them on a graph, and look at the trend line of the points:
But let’s complicate things a bit:
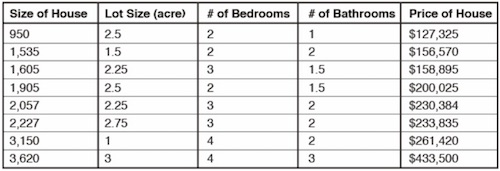
Now we have five different variables across eight different types of houses. The number of possible relationships goes up exponentially. You need only add one more level of data, perhaps these same stats for every city and town across the fifty United States, and the problem grows beyond human ability to solve. This is a great application for supervised machine learning.
Supervised Machine Learning
Supervised machine learning is a two-step process.
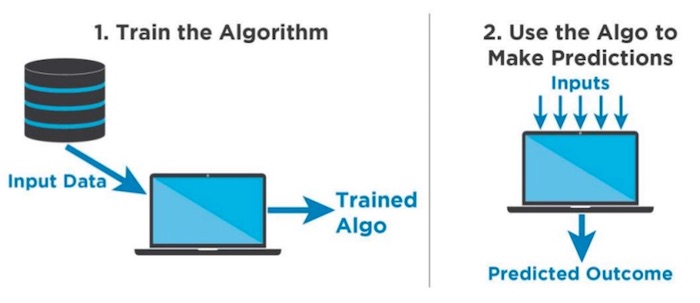
The first step is to collect a lot of data to act as training examples. Then, based on the nature of the problem being addressed, programmers decide on what type of machine learning solution to implement.
In reference to supervised machine learning, you may hear terms such as neural networks, convolutional neural networks, recurrent neural networks, deep belief nets, support vector machines, or other such jargon. Each different type of network has different strengths and weaknesses and is selected to fit the specific training problem that the programmers are trying to solve.
Once this is set up, the programmers feed the algorithm the training data set. This is the data that has been collected, and it has example information, including labels regarding the input information. In my above example for real estate, data such as the location of a house, its size, lot size, etc. are all part of the input information, and the predicted price a given house would sell for is the desired output of the algorithm. Imagine we had such data for 10 million home sales, and all this data gets fed into the algorithm to train it.
During the training process, the machine learning algorithm learns to create an algorithm that can closely replicate the initial data, in this case, the price that a house sold for, based on the input data. This process is quite tricky, and it’s easy for this to result in a bad model – one that matches the training data really well, but does not work well with new real-world information.
There are many things that the programmers must do to tune the process to get a high quality resulting algorithm. It’s quite normal that many different attempts to train an algorithm are needed before they end up with an optimal algorithm. In the “Retweet Predictor” neural network I built, each attempt to train the algorithm required 48 billion calculations, and I probably made 50 different attempts to train the algorithm before I felt I had an optimal result.
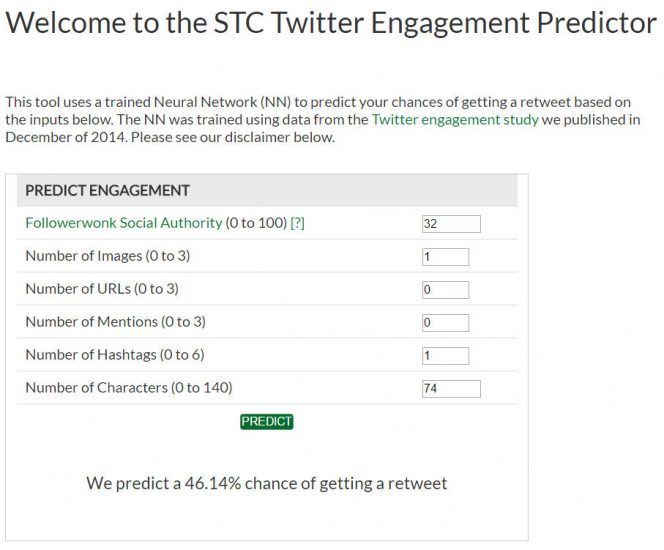
Once the algorithm has been trained, the programmers can now feed new data through it. This could be information about houses that are currently for sale (i.e. they have not sold yet), and the trained algorithm can now attempt to predict the likely sales price as an output.
Facial recognition in photos is another good example of an area to which Google has applied supervised machine learning. Training an algorithm to recognize a face starts by assembling a large number of images that contain faces, as well as a large number that do not. The algorithm can use these to learn the characteristics of a face–two eyes, a nose, a mouth, etc. Facial recognition is something that the search engines are already quite good at doing.
Unsupervised Machine Learning
But what about unsupervised machine learning? This process is quite a bit trickier. One example of this would be the problem of finding relevant news stories.
In Google News, one part of the problem is to find currently trending news stories from vetted news sources. But the second part of the problem is to be able to show related stories as well, and do that “on the fly.”
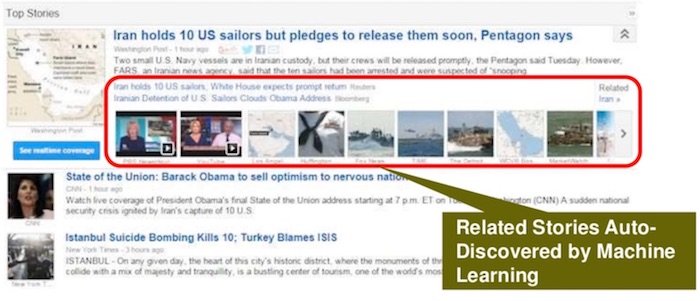
When a news story comes up, quite often it is about something never seen before. This makes retrieving related stories hard, especially when many of those may be just breaking themselves. This is a job for an unsupervised machine learning algorithm.
An unsupervised machine learning algorithm has to be able to look at an input data set and recognize interesting patterns in it, without the benefit of any training data labels. In the Google News case, the algorithm recognizes the nature of the content in news articles, and is able to determine which ones are very similar to one another (that cover the same overall story). This is the underlying process used in Google News.
BONUS: Watch Google’s Gary Illyes discuss machine learning at Google with Eric Enge at Pubcon 2016

Enter RankBrain
The most well-known use of machine learning by Google in its core search algorithm is RankBrain. RankBrain was announced by Google in an interview with Bloomberg News in October 2015. RankBrain is designed to help Google better understand user queries, and has a particularly big impact on longer tail queries that were historically hard for Google to understand.
Language analysis is a huge area of investment at Google (and other major industry players too). Google employs a large team of linguists in a team they call Pygmalion, to continue to drive their understanding of language.
Let’s look at a very simple example of the challenges with machines processing language. Search engines employ a concept called stop words. These are very simple words, such as: a, an, the, didn’t, from, those, and many more like them.
Stop words are filtered out because for the majority of queries they make little or no difference to the meaning of the query. For example, the query “find me the closest coffee shop” is simplified to something like “closest coffee shop”. This simplifying of the query string makes their job easier, and search engines have been using stop words since the very early days of their existence.
However, there are circumstances under which they might make a huge difference in understanding the intent of the searcher. Take, for example, the query “the office.” Before 2005 the stop word “the” was meaningless in this query. We all meant basically the same thing by “the office” or “office.” But 2005 saw the US debut of the wildly popular TV show The Office.
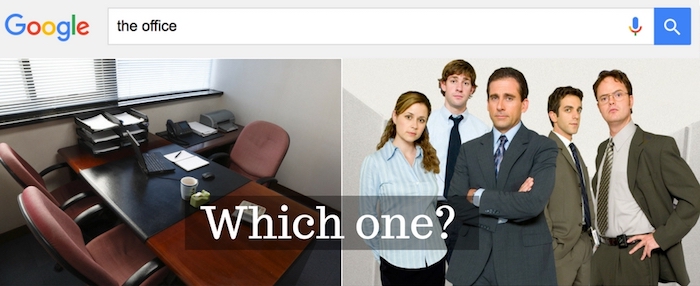
It used to be that if you entered the query “the office,” all the top results were about Microsoft’s Office software. Back in 2005, when the TV show came out, Google had to make some sort of manual adjustment to account for the query “the office.” Ideally, this is something that the algorithm would be able to figure out and handle dynamically. In the case of this historical example, it was NOT RankBrain that handled it, but I offer the example to give you some insight into the complexities of language analysis.
How Does RankBrain Apply Machine Learning?
According to a Google spokesperson I asked about RankBrain, it is “able to represent strings of text in a very high-dimensional space, and ‘see’ how they relate to one another.” Let’s break down what that means.
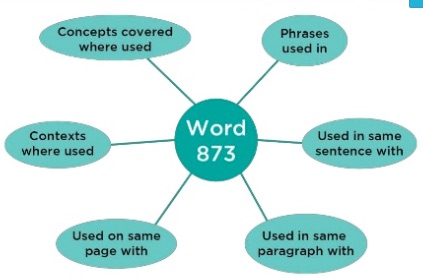
First, every word in the target language is assigned a unique vector number. Then RankBrain scans actual usage of the language and identifies how that word is used in the language in a number of different ways, which may lead to understanding these types of things:
Let’s now extend this conversation to a scenario that Google has confirmed is one that RankBrain addresses. Here is an example of a query where a previously-ignored stop word is critical to the intent of the searcher:
Can you get 100% score on Super Mario without a walkthrough?
Prior to RankBrain, Google stripped the stop word “without” from this query, and that completely changed its meaning. In fact, Google would specifically return pages containing walkthroughs, when in fact what the user wanted was pages that showed how to get a 100% score without a walkthrough. Now, though, RankBrain helps the regular Google algorithm deliver the correct result. (For more on how effective RankBrain is at improving search results, see our before-and-after study “RankBrain: A Study of Its Impact”
What Will Google Machine Learning Algorithms Look For?
Google’s use of machine learning algorithms extends way beyond RankBrain, though, and will certainly be expanded to even greater roles in the future. So what are some of the things such algorithms might be used for in search?
Possibilities include:
- Assessing content quality – Quality is, of course, a subjective term, but there are certain characteristics that most humans recognize as quality, whether consciously or unconsciously. A machine learning algorithm could be trained to look for these, and to rate pages based on the presence or absence of those characteristics. (See also: How Machine Learning Impacts Quality Content)
- Measuring relative authority – Links are still one of the most powerful ranking factors in search, but they also contain a lot of potentially useful information, such as relevance, context, etc., that a machine learning algorithm could assess.
- Social media signals – After a brief experiment with using social media signals, Google abandoned them as too noisy and unreliable of a signal. But it’s conceivable that machine learning could be used at some point to find the signal amongst the noise.
Where Is Google With Machine Learning Today?
While all this is very exciting, and it’s tempting to think that Google must be using machine learning everywhere and anywhere, this is simply not the case. Why not? There are several reasons.
- They need the right training data – They must gather sets of data that will be truly useful in training an algorithm. Collecting a good clean data set is very hard, and in many cases, this is actually impossible to do today, because the data is just too noisy.
- Difficulty of edge cases – Edge cases are areas of ambiguity, definitional imprecision, or rare instances. These multiply rapidly with bigger data sets, and are difficult to account for in an algorithm.
- Length of testing – It takes a lot of time to properly test and train a machine learning algorithm before it is ready to be employed upon actual data. In the case of my Retweet Predictor, each attempted training pass took between 36 and 48 hours to run.
However, we can be sure that despite these difficulties Google is prioritizing areas that could most benefit from machine learning. What areas are those? Anywhere where a solution is beyond human-created algorithms, and for which they can build a strong data set.
How Should We Prepare for Machine Learning in Search?
In assessing the impact machine learning will have on SEO, you should keep several things in mind:
- It’s not going to be the death of SEO (as we know it) – The fundamentals of both on-page SEO and such things as content quality and the earning of good, relevant links, will remain important well into the machine learning age.
- Focus on content quality – As the algorithms get more intelligent they will get better at sniffing out lazy or inadequate content.
- Work on your authority – Do everything you can to become established as a leading expert or trusted resource in your space.
- Increase user satisfaction with your site – Inevitably Google will be using machine learning to assess the meaning of user behavior with your site and related signals across the web. Don’t let them see a sore thumb!
- Create demand for what you do – Search engines want their users to be happy, and a large part of that is giving those users what they want. It’s one reason why certain brands do so well in search: people want to buy from those brands. Be the brand people demand, and Google will have to give you to them.
Let’s go even deeper now, beyond the conceptual, to some actual tasks you can start working on today to be ready for the machine learning age of search:
- Work on building your brand – Related to #5 in the section above, a trusted brand becomes a sought after brand, and Google can’t afford to ignore that. Encouraging the fans of your brand, delivering top notch customer service, keeping the quality of your products high–all of these are actually SEO strategies.
- Create content with recognizable experts – Leverage what Mark Traphagen calls “the power of the personal for brands.” People trust real people before they trust an impersonal logo. Use the power of association: when people see content from your brand created by experts they recognize and respect, that reputation becomes associated with your brand.
- Review engagement data on your major pages – Constantly evaluate the pages of your site that bring in the most traffic, the most links, and get most talked about and shared on social media. Figure out why those pages are so attractive, and do more of that! But also watch for drop-offs, such as main product pages that draw little traffic or fail to convert.
- Check your site search – Make sure you have your analytics set up to capture what people are searching for on your site. This can be a rich source of suggestions for pages you should create, or changes that you should make to existing content.
- Review competitor sites for ideas – What seems to be effective for your competitors? Tools like Searchmetrics, Brightedge, Conductor, SEO Clarity, and SEMRush can help you assess what’s most popular about their sites.
- Perform advanced content comparison analysis – Dig deep to find out content areas your site is missing but that are important to your prospects.
- Think mobile – Design your site to be accessible to smartphone users. Google knows mobile searches already dominate and continue to rise. They will reward sites that provide a better mobile experience.
- Make your site as fast as possible can have a significant impact – Google also realizes that today’s Internet user expects a lightning fast response. Surprisingly, delays of even less than a second can have a large impact on user satisfaction and site revenue.
Are you ready for the machine age of search?
Art of SEO Series
This post is part of our Art of SEO series. Here are other posts in the series you might enjoy:
The way Google has been playing around with Ad positioning and the number of ads in SERP, SEO’s future doesn’t look as bright. I won’t be surprised if Google comes up with Ads for Google Local results soon.
Hi!
Google has been certainly helping us from a long time, especially businesses. Engaging people with your brand is an effective way to increase search ranking and getting more and more traffic to your website. Making the website accessible to mobile users is extremely important as most of the people make search through their smartphones in hands. Creating easy ways for people to get to your website is the most effective way of increasing business. This blog is definitely going to help those who are not updated with the new trends of SEO and machine learning as well as new business owners and SEO practitioners.
In turn, clients and companies can be more efficient, potentially saving money on consultancy fees or improving the effectiveness of an in-house corporate SEO.
Great article Eric. I’m currently learning “Machine Learning” in R and was looking at ways to implement such methods to support my current SEO and web analytics services. It’s of course interesting to see how far google has now advanced in ML and the challenges ahead for SEO practitioners.