Transactional datasets (especially those originating from databases) may contain duplicate records that must be removed before any modeling can begin. There are simply two situations where duplicate records occur are:
- Datasets ARE erroneous (causing the same record to multiple times)
- Datasets ARE NOT erroneous (but records appear multiple times because information is collected different moments in time or other valid explanations)
The truth is, identical records (as errors in the data) should be removed. The question really is how to deal with the second type of duplicate records.
You’re Objective
How you handle the duplicates depends on the objective. If your interest lies in the most recent account that is opened (no matter the type of the account) then only the record with the most recent date of opening has to be retained and the accounts opened on previous dates can be discarded.
An example may be that the records are not duplicated in the sense that all values on all fields are identical, but records are duplicated only on a subset of fields (the customer ID).
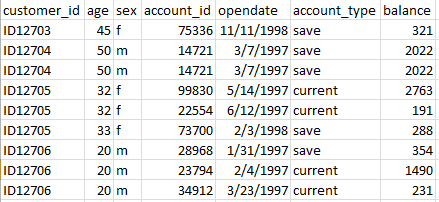
Distincting: Key Fields
To remove duplicate records, key fields need to be specified to define which records are identical. Records with the same values on the key fields are treated as duplicate records. In the example above this means that if all fields are specified as key, then identical records will be identified and the data can be cleansed. To accommodate for the second situation, retaining only the most recent record for the customer, only customer_id should be specified as key field (assuming the data are sorted on “open date” within customer_id).

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
Distincting with the Distinct Node
Using the SPSS Modeler Distinct node (Record Ops palette) checks for duplicate records and either passes the first distinct record or all but the first record) along the stream:
- Add a Distinct node to your stream downstream from the dataset that must have duplicates removed.
- Edit the Distinct node to set the options for duplicate removal.
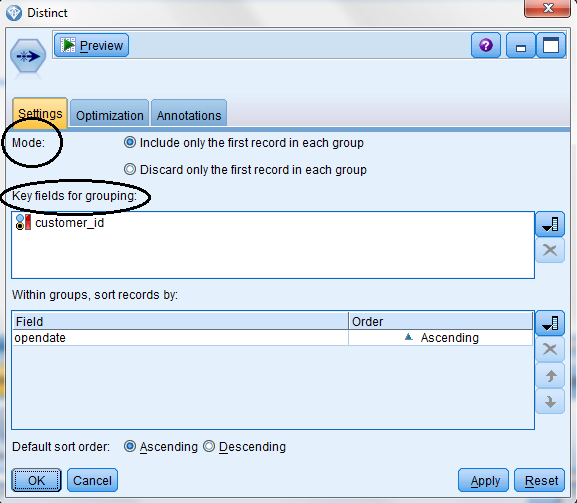
The Distinct Dialog
You will see that the Distinct node has two tabs, Settings and Optimization. To set the options for duplicate removal all you do is:
- Click the Settings tab.
- The Mode controls whether only the first record (within the group of duplicates) is retained, or if all records but the first record (within the group id duplicates) are retained.
- Key fields for grouping should be set to the one (or more) fields that will identify duplicates.
- Within groups, sort records by. You can optionally sort the records within each group to enforce that a particular record (for example the most recent record) is the first record in the group (which in combination with mode, include only the first record, will retain the most recent record).
It really is that easy!