In TM1, you may be used to “integer or string”, in SPSS Modeler, data gets much more interesting. In fact, you will need to be familiar with a concept known as “Field Measurement Level” and the practice of “Data Instantiation”.
In TM1, data is transformed by aggregation, multiplication or division, concatenation or translation, and so on, all based on the “type” of the data (meaning the way it is stored), with SPSS, the storage of a field is one thing, but the use of the field (in data preparation and in modeling) is another. For example if you take (numeric) data fields such as “age” and “zip code”, I am sure that you will agree that age has “meaning” and a statistic like mean age makes sense while the field zip code is just a code to represent a geographical area so mean doesn’t make sense for this field.
So, considering the intended use of a field, one needs the concept of measurement level. In SPSS, the results absolutely depend on correctly setting a field’s measurement level.
Measurement Levels in Modeler
SPSS Modeler defines 5 varieties of measurement levels. They are:
- Flag,
- Nominal,
- Ordinal,
- Continuous and
- Typeless
Flag
This would describe a field with only 2 categories – for example male/female.
Nominal
A nominal field would be a field with more than 2 categories and the categories cannot be ranked. A simple example might be “region”.
Ordinal
An Ordinal field will contain more than 2 categories but the categories represent ordered information perhaps an “income category” (low, medium or high).
Continuous
This measurement level is used to describe simple numeric values (integer or real) such as “age” or a “years of employment”.
Typeless
Finally, for everything else, “Typeless” is just that – for fields that do not conform to any other types –like a customer ID or account number.
Instantiation
Along with the idea of setting measurement levels for all fields in a data file, comes the notion of Instantiation.

The Future of Big Data
With some guidance, you can craft a data platform that is right for your organization’s needs and gets the most return from your data capital.
In SPSS Modeler, the process of specifying information such as measurement level (and appropriate values) for a field is called instantiation.
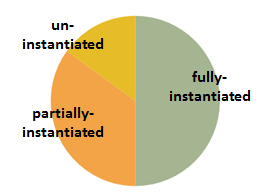
Data consumed by SPSS Modeler qualifies all fields as 3 kinds:
- Un-instantiated
- Partially Instantiated
- Fully Instantiated
Fields with totally unknown measurement level are considered un-instantiated. Fields are referred to as partially instantiated if there is some information about how fields are stored (string or numeric or if the fields are Categorical or Continuous), but we do not have all the information. When all the details about a field are known, including the measurement level and values, it is considered fully instantiated (and Flag, Nominal Ordinal, or Continuous is displayed with the field by SPSS).
It’s a Setup
Just as TM1’s TurboIntegrator “guesses” what field (storage) type and use (contents to TM1 developers) based upon a specified fields value (of course you can override these guesses), SPSS data source nodes will initially assign a measurement level to each field in the data source file for you- based upon their storage value (again, these can be overridden). Integer, real and date fields will be assigned a measurement level of Continuous, while strings area assigned a measurement level of Categorical.
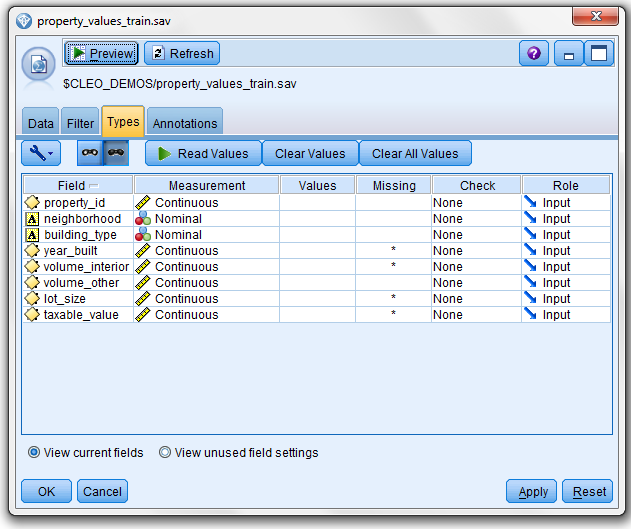
This is the easiest method for defining measurement levels – allowing Modeler to “autotype” by passing data through the source node and then manually reviewing and editing any incorrect measurement levels, resulting a fully Instantiated data file.