A Brief Background
In my previous posts I have walked through setting up Hadoop on Windows Azure using HDInsight. Hadoop is an extremely powerful distributed computing platform with the ability to process terabytes of data. Many of the situations when you hear the term “Big Data”, Hadoop is the enabler. One of the complications with “Big Data” is how to purpose it. After all, what is the point of having terabytes worth of data and not being able to use it. One of the most practical uses is to generate recommendations. The amount of data needed to generate good recommendations can not be understated. To process all of that data you need a distributed computing platform (Hadoop) and algorithms to generate the recommendations (Mahout). Mahout is much more than simply a recommendation engine. Apart from recommendations one of my favorite features is frequent itemset mining. Itemset mining is evaluation of sets of item groups that may have high correlation. Have you ever shopped on Amazon? Towards the middle of a product page Amazon will tell you what items are frequently purchased together. That is what Mahout’s itemset mining is capable of.
Installing Mahout on your HDInsight Cluster
There are a couple things we will need to do to install Mahout.
- Enable Remote Desktop on the head node of your cluster
- To enable RDP on your cluster select “Configuration” and at the bottom of your screen select “Enable Remote Desktop”
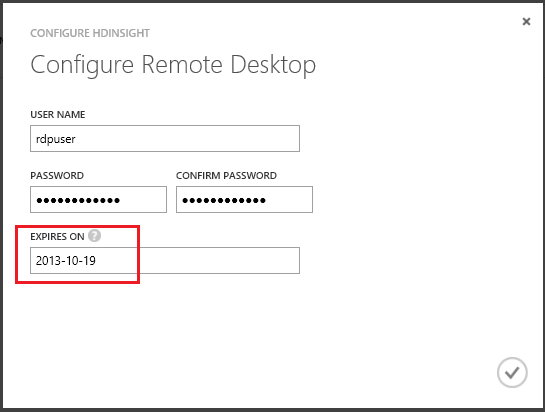
- Enter in a new username and password for the account. You must also specify a length of time that the RDP user is valid for. The maximum time is 7 days.

- Note: While enabling RDP is a nice feature it does not come without its frustrations. The RDP user you create is not an administrator on the server, it is a standard user. There is also no way to authenticate as an administrator. So you will have to deal with things like IE being in Security Enhanced mode and not being able to use Server Manager.
- To enable RDP on your cluster select “Configuration” and at the bottom of your screen select “Enable Remote Desktop”
- Login to your cluster via RDP and download the latest version of Mahout
- Go to the Mahout download site to get the latest version.
- If you click on System Requirements you will see that Mahout has Java as a prerequisite. Not to worry, Hadoop is also Java dependent so there is no need to install Java on your system.
- Extract the Mahout zip file. Rename the extracted folder to mahout-0.8 and copy it to the ‘C:\apps\dist’ folder.

That’s it! Mahout is installed on your cluster! Now lets run a sample Mahout job on your Hadoop cluster.
Running a Mahout recommendation job
The job we will run is from the GroupLens 1,000,000 movie ratings data set. Every data consumption mechanism has a data format that is necessary for proper import. Mahout is no exception. For recommendations, data must be put in a CSV file consisting of three sections; userid, itemid, rating. While still connected to your HDInsight cluster download the data set and extract the contents into a folder (any folder will do but take note where you are extracting it to).
The files we are interested in are ratings.dat and users.dat. The data files are not formatted for Mahout but can be easily converted. Here is a utility that will convert the data for you. Extract the zip file and examine the structure. If you are unfamiliar with compiling and running a program using Visual Studio, I recommend downloading the pre-converted files above.
Note: Due to the Enhanced Security of IE running on your head node, you may need to download the files locally and copy/paste them to your head node through Remote Desktop
Now that the data is formatted for Mahout we can copy it to our Hadoop cluster and run the Mahout job. Open the Hadoop Command Prompt on the desktop of the head node.
Copy both files from your local system to the Hadoop Distributed File System (HDFS) using the command: hadoop dfs -copyFromLocal <source filepath> <dest filepath> (example: my files are located in c:\ so my command will look like this – haddop dfs -copyFromLocal c:\ConvertedRatings.txt sampleInput\ConvertedRatings.txt (run this command for ConvertedRatings.txt AND ConvertedUsers.txt)

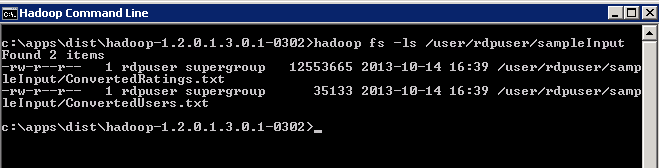
To verify the files copied correctly list the directory contents at the command prompt: hadoop fs -ls /user/<yourRDPusername>/<dest filepath> (example: hadoop fs -ls /user/rdpuser/sampleInput)
Navigate the command prompt to your Mahout bin directory (c:\apps\dist\mahout-0.8\bin). Run the Mahout job with this command: hadoop jar c:\Apps\dist\mahout-0.8\mahout-core-0.8-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -s SIMILARITY_COOCCURRENCE --input=<path to ConvertedRatings.txt> --output=/user/<yourRDPusername>/output --usersFile=<path to ConvertedUsers.txt> ( example: hadoop jar c:\apps\dist\mahout-0.8\mahout-core-0.8-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -s SIMILARITY_COOCCURRENCE --input=/user/rdpuser/sampleInput/ConvertedRatings.txt --output=/user/rdpuser/output --UsersFile=/user/rdpuser/sampleInput/ConvertedUsers.txt )
Note: The portion of the command -s SIMILARITY_COOCCURRENCE should stick out. It is one of the several different Mahout algorithmic classes to run your job on. Going into detail on these is well beyond the scope of this tutorial. If you wish to learn more on them I highly recommend this book.
The process will take approximately 20-30 minutes for a 4 node cluster, but once complete you should see something like this:
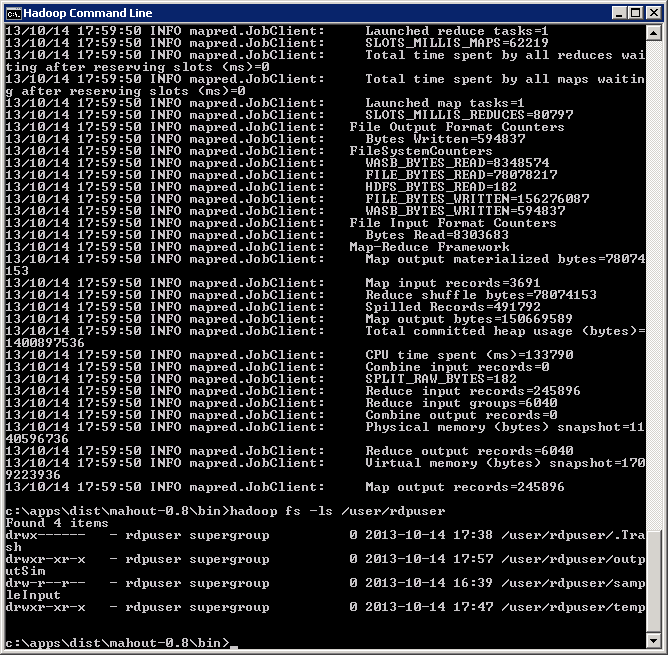
The final step is to copy the output file to your local system for viewing. List the directory contents of the output folder (example: hadoop fs -ls /user/rdpuser/output). Copy the file in the output folder to your local drive as a text file (example: hadoop fs -copyToLocal /user/rdpuser/output/part-r-00000 c:\output.txt)

The text file will contain userids and recommended itemids for those users. It should look similar to this:
You may open the file and notice that there is still work to be done. You have a list a recommendations based on userid and itemid which can’t be directly translated into using in a web or back end application. If you have the users and items already stored in a SQL database then you have the foundation to begin using these immediately. Simply create a new table with foreign keys or you can use a more complete, highly flexible solution called Hive. Hive is another Apache platform that specializes is distributed storage of large data sets. Microsoft has embraced the Apache ecosystem and has created the Hadoop .NET SDK utilizing LINQ to Hive functionality.
Next we will dig into Hive and begin making queries to our Mahout generated data through Hive and Hadoop.