Article Abstract
This article provides a brief overview of all aspects of Google Co-op. It then deals with one aspect of Google Co-op, Subscribed Links, in more detail, providing a discussion of benefits, instructions on how to implement Subscribed Links, and Subscribed Link examples. This article is a follow-on article to several previous articles about Google Co-op:
- “Google Co-Op Overview” which provides an overview of Google Co-op and all of its components.
- “Google Co-Op Topics – Annotating Web Content” which provides more detail on annotating web content.
As a brief recap, Google announced Google Co-op, a beta-test service offered by Google, in May of 2006. Google Co-Op represents Google’s first major efforts to embrace social web and social search. Google Co-op consists of two things:
- Topics, which are a means of labeling web content
- Subscribed links, which are a means for users to subscribe to a particular web site’s content
The remainder of this article will focus on Google Co-op Subscribed Links.
Overview of Google Co-op Subscribed Links
At its most basic, Subscribed Links provide a means for web publishers to add information to the top of Google search results based on relevant search “triggers”. Web publishers do this by submitting a Subscribed Link URL or uploading a Subscribed Link file to Google, and by getting their users to “subscribe” to their Subscribed Link. Web users participate by subscribing to the Subscribed Link of web sites that they find to be authoritative on a particular topic or topics.
The reason a web publisher would participate in Google Subscribed Links is fairly obvious. Subscribed Links gives web publishers another mechanism to make their content available to users. In addition, it gives them a means of placing their content at the top of Google search results above “generic” search results. Here is an example that shows how a Subscribed Link appears in Google Search results:
|
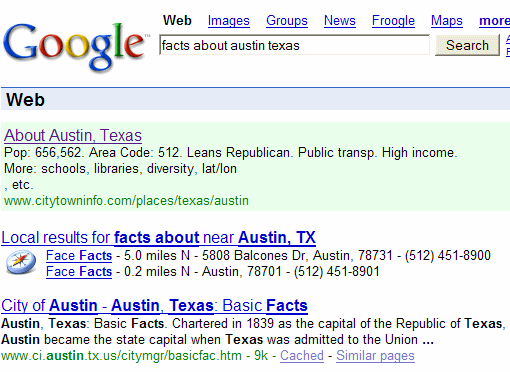
The green shaded area above the organic search results is a subscribed link result. It is easy to see why a publisher would want to get users to subscribe to the feed. It will keep users coming back again and again. In addition, feeds that have a number of subscribers can get included in the Google Co-Op Directory, which will bring new users to their site.
The reason an end user would participate is a little less obvious, but none-the-less still very compelling. By subscribing, users actually alter their own returned search results so that content from sources that they “trust” is brought to the top of their search results above the “generic” search results. For example, if a user likes to travel and they find the content from certain major travel web sites to be particularly helpful, they would subscribe to those sites. By subscribing, they ensure that the content of these sites will be brought to the top of search results when searching on relevant keywords.
Additional benefits to end users are that Subscribed Links may give users a potential means of saving time. The results that they are seeking may actually appear in the Subscribed Links search results, negating the need to click through and search the site. Subscribed Links also gives end users the ability to “vote” on sites that they find to be valuable or authoritative. By going through the process of subscribing to a site, they are in essence casting a vote attesting to the value of that site.
Subscribed Links also brings benefits to Google. As sites gain more subscribers, Google will come to see them as more authoritative. Google will be able to use this information to present high-value, authoritative sites higher up in generic search results.
An overall benefit of Subscribed Links is that the content of low-value or spam web sites will be pushed down in search results as high-value content is brought to the top. Web publishers who offer sites of little or no value, or who abuse Subscribed Links by using irrelevant search triggers to bring up their content, will be “punished” by end users who will not subscribe to their sites or will unsubscribe once they realize that the publisher is not providing any value. This is the primary benefit of socially-vetted web content. Publishers of valuable content are rewarded by the community at large and their content is brought to the forefront. Publishers of low-value content are punished and their content is pushed into the background.
How to Create a Subscribed Link
Web Publishers create Subscribed Links by creating a Subscribed Link file. Google provides web publishers with three ways of creating Subscribed Links:
- By creating a tab separated value (TSV) file
- By submitting an RSS/Atom feed that has been augmented with special tags that define the keyword (search) “triggers”
- By submitting a Subscribed Links file in XML format
Subscribed Links are submitted to Google in one of two ways:
- By submitting a link feed URL. This is the method for submitting links for dynamic content or for content files of over 500KB in size.
- By uploading a Subscribed Links file. This is the method that is recommended for static content and content under 500KB in size.
Creating Subscribed Links Using TSV Files
The most simple way of creating a Subscribed Link file is to create a tab separated value (TSV) file. This is a good means of creating a simple Subscribed Link file that does not need to make use of any of the more advanced features of Subscribed Links.
A TSV file may easily be created with Microsoft Excel, OpenOffice Calc, or any other spreadsheet. The format of a TSV Subscribed Link file is very straight forward (see example below), as follows:
- The first line of the file must literally contain “# subscribed links TSV file”
- The second line of the file must start with the keyword “author”, followed by the name of the author of the file
- Each subsequent line in the file must start with the keyword “item” and then be followed by (in this order):
- A query – the search string that triggers the Subscribed Link.
- A title link URL – The URL of the page/site that the title of the Subscribed Link will link to.
- Body text – this is a piece of text that may be up to 240 characters long that makes up the descriptive body of the Subscribed Link.
- Title text – this is text that may be up to 50 characters long that makes up the title of the Subscribed Link. It is used along with the title link URL to provide the link to a website or page. This item is optional. If it is omitted, the link title will be built from the author name and the link URL.
If a spreadsheet is being used then each of the above four items needs to be in their own column and the spreadsheet must be saved in TSV format.
|
|||||||||||||||||||
Example of a TSV Subscribed Links File
Creating Subscribed Links for RSS/Atom Feeds
A Subscribed Link can be created for an RSS or Atom feed by augmenting the feed with tags from the Google Co-op namespace (http://www.google.com/coop/namespace). These tags do two things:
- The first tag comes in the beginning of the file (in the <rss version=”2.0″> label) to say that you are using the Co-op namespace
- The second tag or tags are used within the item definitions (<item> </item>) to indicate what queries will trigger the Subscribed Link. Multiple triggers may be included for each item.
The following example illustrates this in action.
|
||||||

Example of an RSS File Augmented for Subscribed Links
As you can see, augmenting the RSS feed file is a relatively simple task. Please note that if you are using a tool to create your feeds such as FeedForAll, you need to make sure that the tool allows you to define a namespace for the feed, and the individual tags within item definitions. In the case of FeedForAll, you will need to use the beta version of Version 2. The free ListGarden RSS Feed Generator Program from SoftwareGarden also supports namespaces and namespace tags.
Creating a Subscribed Link Using an XML File
Creating a Subscribed Link by creating a Subscribed Link XML file is the most difficult, but most powerful way of creating a Subscribed Link. At its most basic, an XML Subscribed Link file does two things:
- It defines a query (search string) or queries that will trigger the Subscribed Link. Queries should be relevant to the content of the link.
- It contains the results, or the output – the information that is returned by the Subscribed Link in the Subscribed Link box above generic search results.
The devil is, of course, in the details. Taking this a step at a time, the Subscribed Link file should start and end withResults tags as follows:
|
|||||
The second line of the file, which is optional, is an AuthorInfo tag which provides author name and a summary of the Subscribed Link, as follows:
|
|||||
The “meat” of a Subscribed Link file is defined in what are referred to as ResultSpecs, which, you guessed it, are between ResultSpec tags (<ResultSpec> </ResultSpec>). A Subscribed Link file may define multiple ResultSpecs. EachResultSpec must have a unique id (<ResultSpec id=”ResultSpecExample”> Each ResultSpec contains two things:
- A query. A query is a search string that triggers the Subscribed Link. It may be a literal text, regular expression matches (more on that later), or a search pattern or variable. Each ResultSpec may contain more than one query. Queries should be related to the defined output.
- A response. A response is the text and link that are returned for the defined query. It is formatted as a heading which is also a link, and up to three lines of body text, thus a response must define the following:
- A title. This is both the title of the response and the text for the link. The title may be a maximum of 50 characters.
- A link URL, which Google refers to as a more_url (in essence, where to go to get more information). This is combined with the title text to form the link. URLs may be up to 200 characters long and must omit the “http://”. Google “recommends” that output be plain text that is free of HTML tags. If HTML tags are used, they must be “escaped” (normal text).
- The first line of body text, text1. The total length of this line cannot exceed 80 characters.
- The second line of body text, text2. The total length of this line cannot exceed 80 characters.
- The third line of body text, text3. The total length of this line cannot exceed 80 characters.
Putting this all together, a ResultSpec would look as follows:
|
|||||
In the above example, the query is “301 redirect” which provides the above defined response. While that is a good start, individuals may actually search on multiple different terms trying to get the same information, such as “redirect”, “html redirect”, “url redirection”, and more. In order to take this into account, you need to define a more sophisticated set of queries. You could do this by defining multiple individual queries in the ResultSpec. Google also allows you to define variables, or what they refer to as “query patterns”, to handle multiple queries. You do this by defining DataObjects. DataObjects have a unique id, as well as a type. The type is, in essence, the variable name. To define a query pattern for our 301 redirect example would look as follows.
|
|||||
In the above example, the query pattern, or variable, that you define is called “Redirects” (the type defines the variable/query pattern name, which is used in the query in brackets “[Redirects]”). The QueryName value tags define the possible values for the variable. A search on any of these values will match the query and trigger the Subscribed Link response.
Google also allows you to define output variables, variables that you use in your Subscribed Link output text. These are defined as attributes to the query pattern variables. You can think of these almost as sub variables of the query pattern (see the example below). In the following example we define three attributes to the “Redirects” query pattern variable – “fullname”, “unix_linux_servers”, and “windows_servers”, and assign each of them a value. We then make use of these variables in the “title” and “text3” output.
|
|||||
PLEASE NOTE: You will notice the “0.” in front of the attribute names used in the output text. That is because you need to indicate that you are using the attribute for a specific variable in the ResultSpec. In this case, the first variable used in this ResultSpec is “[Redirects]” (it also happens to be the only variable used). “[0.fullname]” literally means that you are using the “fullname” attribute for the first variable (“1.attributename” would indicate the attribute for the second variable in the ResultSpec, “2.attributename” would indicate the attribute for the third variable in theResultSpec, etc.).
What Subscribed Links Look Like and Output Formatting
Subscribed Links, triggered by relevant queries, appear as a “Subscribed Link” box above generic search results. The example below was triggered off of the “301 redirect” Subscribed Link example (from above).
|
|||||
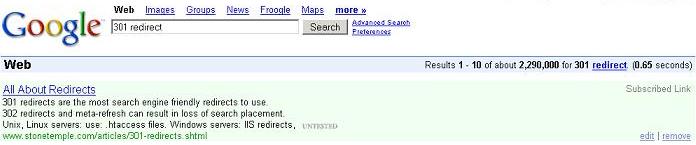
Google does allow you to alter the appearance of this box to some degree. You may include links in your output body text (Output name=”text1″, Output name=”text2″, and Output name=”text3″). You do this by defining up to five link text/link url pairs. For example:
|
|||||
Note the <Response format=”answer_right”> tag. If this were omitted, the link text/link would appear to the left of the line followed by the other body text.
A Brief Overview of Subscribed Link’s Advanced Features
Google Subscribed Links also provide many “advanced” features. Advanced features of Subscribed Links is a deep enough topic to be the basis of its own in-depth article. This overview will simply provide a brief description of the advanced features to make you aware of them. If you would like to go into them in more detail you should consult theAdvanced Features section of Google’s Subscribed Links Developer Guide.
Following is a listing of Subscribed Links advanced features:
- Using Multiple Files – You may submit multiple files to create your Subscribed Link. The resulting Subscribed Link is the combination of all of the files. Note that you must maintain unique IDs for all ResultSpecs and DataObjects across all the files.
- Using Brackets and Backslashes – to include brackets [] in your output you need to precede them with a backslash (for example: \[\]). To include a backslash in your output, you must precede it with a backslash (for example: \\).
- Special Object Types – Google provides four object types (variables) for which you do not have to defineDataObjects. These are:
- Cities – [City] will match on cities and towns in North America on city name with state (for example: Boston, Massachusetts) or just city name for large cities (for example: Boston). This may be used in a query pattern and its attributes (“fullname”, “abbrev”, and “zipcode”) may be used in your output text.
- Regular expression matches – You may use Perl compatible regular expressions (PCRE) to perform text pattern matching.
- Dates – Google has defined the date variables “date”, “timeofday”, and “timerange”, each with its own associated attributes.
- Calculator outputs – You may get results from the Google calculator using the element type “calculate”.
- Extractors – You use extractors with regular DataObjects to extract attribute data that can then be used to construct queries that match against QueryName query patterns.
- Validators – Similar to an Extract tag, Validate tags are used on query pattern attributes to do matching between two attributes (if they are equal than the Response is displayed)
- Reference Attributes – A reference attribute is an attribute that refers to another attribute rather than a string literal – a variable pointing to another variable instead of containing a value.
- Using the Raw Query – You may use the special object [q] to make use of the raw query in Extract, Validate, or Output tags.
- URL Escaping – Converting spaces to +’s, & characters to & and so on.
Best Practices
Google does provide some guidelines for “best practices” when creating Subscribed Links. Perhaps the most important guideline is that Subscribed Links should only trigger on queries that are relevant to their content. Google feels very strongly about this, going so far as to say: “if your results flagrantly violate the principle of triggering only on relevant queries, Google reserves the right to disable their display entirely…”, per their Terms of Service.
Other guidelines include:
- The title of your output (Output name=”title”) should be in proper sentence case (first word capitalized, only proper nouns capitalized thereafter).
- In outputs, you should not make excessive use of capital letters and non-alphanumeric ASCII characters.
- Output body text (Output name=”text1″, Output name=”text2″, and Output name=”text3″) should provide information that is immediately useful and relevant to the defines queries. The output should not simply contain generic advertisements for your goods and services.
Again, “If your results flagrantly violate these guidelines and produce a bad user experience, not only will users tend to remove them, but Google also reserves the right to disable your results entirely, as described in the Terms of Service.”
Additional Information
There are many good places to find additional information. The first is the Google Co-Op Site(http://www.google.com/coop) where they have posted a Subscribed Links Developer Guide. The Google Co-OpFAQ is also helpful. There is also a good article entitled “How to Use Google Co-op” at Google Blogoscoped.
Conclusion
While still in its infancy, but maturing quickly, Google Co-op Subscribed Links shows a lot of promise on many fronts:
- It provides a powerful tool for web publishers to make their content available in a very relevant and compelling way, and at the top of generic search results.
- It provides end users with a powerful means of enhancing their search experience and results, providing them with content from “trusted” sources and helping to filter out or push low value content down in search results.
- It should enable Google to provide much more powerful and relevant search results to users over time, further enhancing the user search experience.