
Stefan Weitz
Stefan Weitz is a Director of Search at Microsoft and is charged with working with people and organizations across the industry to promote and improve Search technologies. While focused on Microsoft’s product line, he works across the industry to understand searcher behavior and in his role as an evangelist for Search, gathers and distills feedback to drive product improvements. Prior to Search, Stefan led the strategy to develop the next generation MSN portal platform and developed Microsoft’s muni WiFi strategy, leading the charge to blanket free WiFi access across metropolitan cities. A 13-year Microsoft veteran, he has worked in various groups including Windows Server, Security, and IT. Stefan is a huge gadget ‘junkie’ and can often be found in electronics shops across the world looking for the elusive perfect piece of tech. You can follow Stefan on Twitter
Interview Transcript
Eric Enge: Let’s talk about the near and longer term frontiers of search. One recent notable event was the Google Panda algorithm change, which caused big waves. I classify changes like Panda as an overt attempt to measure content quality or user engagement. Would you give us your thoughts on that?
 Stefan Weitz: Google’s Panda Update was an interesting event. I saw reports recently on DemandMedia showing they were down 40% on their traffic. What this speaks to is the necessity to look at page level quality. I think one of the things that started the work on Panda was the JC Penney paid link issue which called into question the quality of PageRank.
Stefan Weitz: Google’s Panda Update was an interesting event. I saw reports recently on DemandMedia showing they were down 40% on their traffic. What this speaks to is the necessity to look at page level quality. I think one of the things that started the work on Panda was the JC Penney paid link issue which called into question the quality of PageRank.
Google initially responded by blocking the entire JC Penney domain for a few days. We thought that hurt the users because we did the same thing in a test. We blocked all JC Penney internally and asked our human ranking systems “does this result for the search phrase “comforters” look better or worse after this change?” Everyone said it looked worse because they expected to see JC Penney there.
Page Level Classifiers
Stefan Weitz: What it told us was there are different ways to classify the quality of pages. We have page level classifiers that look at every page we index that attempt to discern a quality score. It looks at things like reading levels, number of ads versus content, length of words, length of a page, all those standard things, and some not so standard things as well.
It looks beyond the links coming into the page and beyond the easy things, like counting words on a page, and uses semantic technology to figure out what it is that page is discussing and if it is high quality. So, yes I think you see some similarity between what we are doing and what Google is doing.
Eric Enge: You mentioned that the ratio of ads to content on a page would be one metric. Another one might be how the ads appear, how prominent they are on the page. But doesn’t that entail a lot of sophisticated CSS analysis to determine what objects are on a page?
Stefan Weitz: Yes, this is not an easy thing to do at the page level. It might be easy for someone to say that for a domain like eHow, we should apply a blanket kind of deprecation of their rank. That is certainly a way some folks have wanted to go about this. Blekko does this today with their engine; however, we think it is better if we do the costly way of looking at page level analysis.
To your point, you can’t always tell at the computer level and algorithm level what the page will look like at the end, especially if the page requires some input or is a dynamic page. Generally, we get a good idea by using domain-level classifiers to say this page looks suspect and if we know the domain itself tends to be 84% suspect, those two factors alone give us hints about the quality of that particular page.
Lexical Analysis
Eric Enge: Is there any semantic or lexical level analysis you can do to get signals of that kind?
Stefan Weitz: Yes, absolutely. Lexical signals help us determine the reading level score, which we have used for years; for example, how advanced is the language, how complex are the phrasings and the noun and adjective agreements. Also, if we see a page title of Canon camera, but the body talks about vacations in Hawaii, then we know there is a mismatch which gives us hints as well.
Eric Enge: If someone uses advanced language and it looks like a sophisticated document, that would suggest that it is not a good match for some searchers and to others that it is, right? Is this a way of classifying and matching up the sophistication level of the document with the sophistication level of what the searcher is looking for?
Divergence from Google
Stefan Weitz: I don’t believe we are quite there but you are highlighting one area I am beginning to see us and Google almost diverge. They are very focused on link level analysis and understanding what pages to return to a query which is important for the kind of web we have talked about for many years. However, we are beginning to look at the web differently than they are.
The web is becoming this rich canvas that represents all things you and I touch and interact with every day.
We look at the web as a digital representation of the physical world. The web is becoming this rich canvas that represents all things you and I touch and interact with every day. When you start moving to that level of thinking, the notion of links to keywords is important but it doesn’t serve us as well if you move into, what I like to call, a web of verbs versus the web of nouns that we have been living with for so many years. I think that’s when search starts getting to things like social, services and geospatial which all become more prevalent as we begin to think of this web as a high definition proxy for the physical world.
Eric Enge: Let us expand on this notion of verbs. Give me a practical example or two of how that plays out differently as opposed to a noun based analysis.
A Web of Verbs
 Stefan Weitz: Let’s step back and examine how the web was. First, let us stipulate that the structure of search is really predicated on the structure of the web itself. What I mean is, if you think about Berners-Lee and the work they did, they codified HTML and HTTP as the underlying structure of the web as we know it and that yielded a bunch of pages, a bunch of text pages and a bunch of links. Those links, in many cases, were anchor text that pointed to a particular page.
Stefan Weitz: Let’s step back and examine how the web was. First, let us stipulate that the structure of search is really predicated on the structure of the web itself. What I mean is, if you think about Berners-Lee and the work they did, they codified HTML and HTTP as the underlying structure of the web as we know it and that yielded a bunch of pages, a bunch of text pages and a bunch of links. Those links, in many cases, were anchor text that pointed to a particular page.
That allowed engines to say, even though I see this URL is iflyswa.com, which was Southwest’s old URL, the fact is that I have eight million pages pointing to this URL with an anchor text of Southwest Airlines. That allowed the search engines to make that association so when someone typed in “Southwest Airlines,” they could conclude that the searcher was looking for the domain iflyswa.com. What that did was make searchers think about search as a tool to find something else, a noun based search.
Even though our intents were action based … we defaulted back to this navigational model … because we assumed the search would fail if we attempted to do something more advanced.
If we thought “I have to check in to a flight on Southwest” we rarely if ever, would type “check-in Southwest Airlines flight 858” into a search engine because we knew it would fail. Even though our intents were action based, or verb based, we defaulted back to this navigational model, or noun based model, because we assumed the search would fail if we attempted to do something more advanced.
Eric Enge: Or if we tried something more advanced, it failed, so we backed off.
Stefan Weitz: Precisely, and most people assumed search is good for 2.2 keyword searches and that’s all.
 That’s where we were, that’s the web of nouns. We had this great web of nouns and the connective tissue among all the pages linked that defined this noun based web. Now we are getting more into this action or verb based web. If I type in “book a romantic table in Austin, Texas next week for two at 7 p.m.”, the search engine can now understand that query at a semantic level, understand the nuance of what I am asking, and then because there are enough services opening up their protocols and their APIs, Bing can then broker out that request to a number of different services across the web and stitch that information back together to help me go from “I want to do this” to “I have done it.” That’s the web of verbs which is this whole separate web, if you will, that’s been evolving over the past couple of years.
That’s where we were, that’s the web of nouns. We had this great web of nouns and the connective tissue among all the pages linked that defined this noun based web. Now we are getting more into this action or verb based web. If I type in “book a romantic table in Austin, Texas next week for two at 7 p.m.”, the search engine can now understand that query at a semantic level, understand the nuance of what I am asking, and then because there are enough services opening up their protocols and their APIs, Bing can then broker out that request to a number of different services across the web and stitch that information back together to help me go from “I want to do this” to “I have done it.” That’s the web of verbs which is this whole separate web, if you will, that’s been evolving over the past couple of years.
Eric Enge: Another simple example would be “buy a digital camera” which is fairly straightforward and a noun based web handles that reasonably well, but there are many other queries such as “book a romantic table”, or “learn about diabetes”, which won’t work well if you want to learn enough to write a paper.
Stefan Weitz: Correct, because the web, up to this point, has been about navigation, finding something to then do something with. The search of tomorrow is more about actions and decisions, not just about finding. You can do much more on the web than you could a decade ago when search was pioneered.
Social Signals

Eric Enge: What is the timeframe in which you see this unfolding?
Stefan Weitz: Well, a number of factors come to play. The first thing we see helping this trend along is the social infusion into search. Traditionally, if you were to make a complex decision using search, you would stumble around, look at a bunch of links, hope you find some information, and then probably end up giving up and asking a friend or calling a buddy. Humans have this primal behavior around the social experience where we almost always ask our friends and acquaintances for advice.
Part of what this new verb based web is turning into is the ability for us to connect up queries with people who could help answer those queries more effectively. We are doing this in Bing with Facebook and Twitter, so when I do a search for “parasailing Maui” in Bing, if any of my friends anywhere have liked any link across the entire world wide web, I am going to inject that link into my results page. That’s a fairly primitive example.
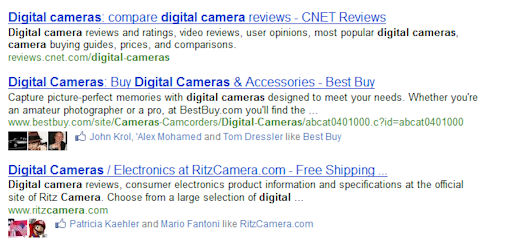 |
From a Computer Science perspective, it is actually a phenomenal example, but from a UX standpoint, you and I look at that and say it’s just okay. But think of the power there, what we have done is removed all that time you spent looking through bad links, or trying to figure out which one of your friends have been to Hawaii in the last year, and we literally take the digital traces people leave across the web and infuse those directly into the search experience. That’s a pretty profound change in how search works.
Wisdom of the Crowd
Eric Enge: That works as long as your social network has the answer somewhere in it. For example, if you don’t have a friend who has been parasailing in Maui, they may not be able to help you answer that question.
Stefan Weitz: Right, so for those examples, you get into things such as the aggregate wisdom of the crowd to help answer those questions. You start looking at Twitter updates to see if anyone has Tweeted about the experience of parasailing in Maui. We are trying to take that which you do today and get constant affirmation or decision help from all your acquaintances and inject that real-time into your search. However, you are right, if no one you know has information on your particular search, then you are relying more on the wisdom of the crowd to help find that information.
Eric Enge: If I were to try to present a picture at a high level, what you see happening is the social interactions, whether it be with your immediate friends or the wisdom of the crowd, is going to be one of the dominant forces on the web. The task then is to leverage those networks as an information source.
Stefan Weitz: That is correct. Also, you can think of it as the first implementation. As people leave more traces of their physical self in the digital realm, the ability for us to process those traces and do interesting things with them escalates.
Privacy
Eric Enge: The next logical question is will there be some privacy kickback which could be a threat to the accessibility of those digital traces?
Stefan Weitz: For us, it comes down to three big principles: make sure it is transparent, make sure it is controllable, and make sure there is a value exchange. If we are using something to personalize your experience, to make your experience better, you should know that, and here is what we know about your search history and you can go see it easily on Bing. The control aspect is how do we make sure you can shut it off and how do you delete things, whatever those things might be.
The last thing, which is most important to me, is what are you getting in exchange for that information? That is the same argument used for a long time with Amazon. The fact that I buy 80% of my stuff on Amazon means they have a lot of information about me. I am okay with that because the value I get out of it is pretty high as I get recommendations and discounts.
If it was a third party aggregator who took that information and offered me zero value, I would be more reticent to let them use my information. So, these are the kind of principles we have. I like them, I think they are good and that is how we design all products.
Leveraging the Search History of Others
Eric Enge: Do you envision a situation where you will know that Joe has just searched on digital cameras on Facebook, no one in his direct social networks has actually Tweeted or done a Facebook update related to that, but you know his friend Suzie did a similar search two weeks ago. Do you picture that level of data being available?
Stefan Weitz: Certainly. We will look at second order networks, and since you know somebody who knows that person, present that information on top. What you are asking about is something I am a big fan of, expertise-based matching. Forget whether or not you know Suzie. That might be less important than the fact that we know she is an expert in parasailing.
Because of all the traces she left, we can devise that parasailing is one of her key interests. Also, she is quoted a lot and re-Tweeted a lot which makes her an authority on that topic. You can begin to understand the power of leveraging those social traces. All the things she did across the web could influence the result page directly because we know that she is influential on that topic.
Eric Enge: So this makes her a very interesting computer science problem.
… you have to look at every single friend and their entire legacy and decide that one of the hundreds or thousands or millions of URLs that your friends have liked is a good match for the query terms you put into Bing, and then do that within ten milliseconds.
Stefan Weitz: Isn’t it cool? You would appreciate this as a person behind some of the earliest computer science at Phoenix Technologies (editor’s note: Eric worked at Phoenix Technologies earlier in hi career). The amount of computation that must happen for every search you do, you have to look at every single friend and their entire legacy and decide that one of the hundreds or thousands or millions of URLs that your friends have liked is a good match for the query terms you put into Bing, and then do that within a few milliseconds. It is one of those computer science problems that are amazing to solve at that scale.
The Bing Landscape Today
Eric Enge: This will likely happen in stages for exactly that reason. Would you talk about that part of the landscape today in terms of what you are doing?
Stefan Weitz: Since October, we have had the Twitter augmentation. That was interesting because it attempted to provide a layer on top of the Twitter fire hose. We tried to find the most reputable people who are Tweeting, we tried to de-dupe things, and take out spam and adult links and make it so even my mom, who doesn’t have any idea how one can use Twitter, can go and type in “hair gel” and get back Tweets that make sense.
Then of course, we have the Facebook deal, inked and done. Since last October, it has been about how we leverage those billions and billions of data points that we see from Facebook into the results. We have recently launched Like annotation which means if there is any URL on any search page that any of your friends have ever Liked, we will show that they liked it.
We will actually carve out a big space on a page and say Paul Liked this link. Also, we are getting into the people search arena where we find people you may know. For example, if you are at a party or a business event and you met someone but can’t remember their last name or you don’t know how to contact them, the people search, which itself is 4% of the queries we see on the web, is a helpful tool for social.
Over the next several months you will begin to see more use of Facebook data, a better people search, and you will see us leverage more than just the Likes. Information about the person will be taken into account in different ways across the Bing search engine that extends beyond what they liked.
Eric Enge: For example, today there is a volume of Likes that a page has and, particularly, if it is Liked by your friends, that carries weight in terms of returning the results for a particular user.
Stefan Weitz: Yes, if you have friends that Liked particular results, that will tend to show up higher on page 1. As an example, I never watch sports and I recently did a March Madness query. One of my friends, Kelby Johnson, Liked an add-in to Outlook which added all the March Madness games to an Outlook calendar.
That’s interesting because the link that Kelby shared would have not normally appeared in the standard ten links for the query March Madness, but since he is a friend of mine and because he shared it on Facebook, it appeared on position 4 on the page.
I know Kelby is a sports fan. I trust what Kelby says about March Madness is going to be of high quality. It is much more like a one-to-one type scenario.
Wisdom of the Crowd
Eric Enge: I get the one-to-one theme, but if you don’t have a friend that happens to be an expert, you can always fall back on the volume of Likes that represent the wisdom of the crowd, right?

Stefan Weitz: Yes you could (although we don’t do that now), and we use the volume on Twitter because they help us understand what should rank well for news. For example, we are seeing many Tweets on Libya. That can help us understand that we should look at the news and make sure we index what is going on. There is magic that happens as we identify trending topics from social networks.
Eric Enge: You mentioned Twitter and news being an obvious application to Twitter because of the recency effect, an example of which is finding out about earthquakes on Twitter long before you would find out about them anywhere else. I will call that a vertical application. Are there other types of vertical applications which Twitter and/or Facebook are particularly well suited to?
Stefan Weitz: That’s a good question. You mentioned the news and we started embedding Twitter Tweets into the news page itself for that very reason. If you start searching for North Korea, or some newsworthy event, you will see it on the right-hand side, the actual real-time updates on North Korea, so that’s obviously a big one.
Facebook check-ins
The other things we are seeing are check-ins on Facebook. When you see many folks checking into a particular location and see whether there is an event or something else going on at that location. That helps us understand, for the local angle, what restaurant is popular now. That is interesting information to look at.
Eric Enge: If you are looking for a place to eat while in Seattle, and you type in “Italian restaurants Seattle”, or something like that, you can return in the results which of your friends are currently at Baluchis and you might want to go there because Joe and Susie are there now.
Stefan Weitz: Yes, or say in another analogy, they liked this in the past or they checked in here in the past.
Another example, maybe its Friday night, you are young and you want to go out clubbing so you could leverage that Facebook check-in power to be able to see what looks like the hottest place now based on check-ins.
Eric Enge: More check-ins is an indicator that it is hot.
Stefan Weitz: Precisely, but what you are identifying is there is all this data and the challenge is to write filters to parse or piece these things out and say what is the use case, what is the scenario where that piece of information or that set of information can help make a decision. The nano footprints and digital traces people are leaving are incredible, and we have never seen this level of data in all of human history in a way that a machine can read it. It is truly one of those things that I am literally awed by.
Eric Enge: One of the interesting challenges though, only about 7% of the US population is on Twitter. That means there are many people who aren’t in that environment.
Stefan Weitz: I think you see this in the example of my mom and Twitter. She has no interest in Twitter and doesn’t know what she would say on Twitter, but she can benefit from the folks who are on Twitter. The second interesting thing is something I spoke about with David Kirkpatrick, who published the Facebook Effect book, a few weeks ago. He mentioned the fact that he doesn’t think people know how much they are broadcasting online.
Computational Challenges!
From a computer science standpoint, you now have this ability to do amazing things with all this data and, in a very positive way, you can help people make better decisions and do things faster because we are able to predict or help with these things in a computationally efficient way.
I was supposed to be at Cray Computing today which is based in Seattle. They are having a symposium on parallel processing and very large graph data sets. When you get into this level of graph data, which is often reminiscent of semantic triples, traditional commodity computing starts to become less and less efficient. We need other ways of handling those graphy data sets.
… the computational model is going to move away from purely commoditized and more towards a system which can begin to make sense of data.
Cray and Bing have some cool stuff around vector scaling but I think the computational model is going to move away from purely commoditized and more towards a system which can begin to make sense of data. This is similar to the way we built Farecast which analyzes a billion and a half price points a day for airfares and attempts to synthesize that data into something humans can use. Those are very specialized filters on the web. We see more and more of those specialized filters being developed to preprocess the web for people in a way that helps them get things done. It is exciting.
The impact of apps
Eric Enge: A couple of years ago, we might have referred to some of these things as vertical search. Expanding into a services conversation, you have a growing family of these services which are evolving, to use your phraseology, to verb oriented. I want to do this, I want to do that. Can you expand on that a little bit?
Stefan Weitz: I think I go back and forth on this. A while ago I wrote something called App-ocalypse because I was lamenting the fact that we had half a million apps across the two big global platforms. I commented on how chaotic that was, the fact I needed to install an application on my device to figure out how to get from the Lower East side to 57th in Manhattan.
I had to understand what app to install, decide if I wanted to make the purchase, install it, and then wait for it to load and install while waiting in the cold. When all it was doing was brokering a request out to a particular data source.
Eric Enge: You also had to decide which version of the app would work on your platform.
Stefan Weitz: It has gone better with the marketplaces, with iPhone and Android, Windows Phone 7, but it is still chaotic to me. There are many applications which are simply front ends to data sources. The problem is the average consumer doesn’t want to spend time figuring out what they should install so they are losing out on the richness of the web. The positive is that many of these application developers or sites are developing these apps so they can be accessed via programmatic means, like an API.
In the early days, we had the UDDI notion, Universal Description, Discovery, and Integration, the concept was that we would have this published schema on the web of all the web services that a developer could call. We are getting back to that. If I want to book a table, as an example, I know there are a few services I can call up, such as Urbanspoon or DinnerBroker. I can call their APIs on the web and actually broker that information into my search results.


If you type “Gennaro’s in Boston” in Bing, we know it is a restaurant query, we know it is in Boston, we will say the likely intents for that query are to find reviews, to find photos and to book a table. Those are three likely intents we see for restaurant queries in Bing. Bing will check, do we have OpenTable? Yes we do, so we can broker that experience right into the Bing interface while you complete the action from Bing. You are going to see more of the application ingestion or the application exposure inside the search engine.
Eric Enge: You are virtualizing that whole experience and they don’t have to figure out how to install the app, and configure it, and remove the platform issues. Those issues are getting better but will never be totally solved because every time a platform becomes standard it creates an incentive to differentiate.
Stefan Weitz: Exactly. OpenTable would say we also like folks coming to our site because it increases loyalty and they get points and that makes sense. But in many cases, there are opportunities for search engines to say I am not going to simply index pages anymore. I am going to index services as well and I am going to index the real world, the geospatial world as well to build out this comprehensive model of the world in which we live. Then, once we understand the intent of the searcher, we can connect up those resources in intelligent user experience. That’s the holy grail.
For the last twenty years or so, we have been hearing about semantics, and services, and web services, and mapping. Remember Mobile coupons was a big thing a decade ago? You are going to walk by Starbucks and boom you are going to get a coupon for Starbucks on your phone. We have been hearing this every year for the last ten years, that this is the year we are couponing, well suddenly look at what has happened.
In the last eighteen months, you literally have things like Facebook Open Graph which defines a pretty loose, but still a usable, semantic model for objects across the web. Using the Facebook Open Graph, you literally can tag your page as a movie page, so you know that this is a movie. That’s a big deal from a semantics’ standpoint. You have Groupon or LivingSocial for mobile couponing. You have Facebook and LinkedIn and Twitter all helping us understand your social relationships or your comments on things, and blasting them out to the web in a way a machine can read them.
All, or most, of the things we have needed in the last two decades, have begun to become tangible and real in the last eighteen months. I can finally see all the pieces coalescing and coming together. In the next twenty-four months, you are going to see from us an acceleration of this, the likes of which I don’t think we have seen in the search space. I will give you an example. We did some work with movies with MS research called Project Leibniz, which is named after the famed physicist and mathematician.
Digitizing the Real World
Stefan Weitz: Project Leibniz began by trying to understand at how we could look at a movie as a physical object in the real world and not simply a page on the web. We know that some page about Casablanca could refer to the actual movie, and movies have characteristics, they have attributes, they are an object. We begin to ascribe all these traces back to that “Casablanca” object, all the characteristics that make it up in the real world. Here is the packaging, the graphics about it, who directed it, when it was released, everything.
If you go to Bing and search for a movie, what you get back is not simply a page that points you to all the pages on Casablanca, we show you a page informing you where you can watch it and eighteen thousand reviews from across the last hundred years of cinema. This is possible because we now understand that movie as an object. That is going to be applied across more and more physical things over the next eighteen months or so. And the fact that we know the connections you have and what they are doing, you are going to see a huge amount of work there as well.
Eric Enge: We haven’t really touched much on geospatial so can we dig into that a little bit?
Stefan Weitz: Sure. I use geospatial, and I probably should do a better job characterizing it. It is about digitizing all the objects in the real world. The Casablanca movie is a good example. As you get into more of the core physical world of reconstruction, you see things like the new Panorama app for iPhone. I think it is not appreciated for all of its value. You have this free app which anyone with an iPhone 4 can install.
The ability to crowd source the world and get this data from a number of devices is something we have never seen at this scale.
A person can walk into their business, turn on the button and create a three-dimensional view of their entire business in about two minutes on their device. They can hit a single button and upload the panorama including their lat and long and suddenly create something which would’ve taken thousands of dollars and weeks of processing to do. The ability to crowdsource the world and get this data from a number of devices is something we have never seen at this scale.
Companies like INRIX are embedding sensors inside of GPSs that will pull back traffic data on side streets. You now almost have this problem of too much data coming in. I think it is interesting for query resolution, but also for living your life on a day-to-day basis.
As far as your question, “what can be done to improve the data in local business search?” we recently launched the Bing business portal which is a major upgrade to what we had. It allows you to upload photos, all those things are now built into the system. One of the most interesting things that local businesses can do, which isn’t often talked about much, is to make sure your social presence is as important as your standard digital presence. If you are a hotel you can have people on Trip Advisor, or Yelp if you are a restaurant, or if you are a plumber on Facebook or Twitter, the social signals that people will generate about your business will continue to amplify your importance online.
Businesses that are 1-person or 2-person shops don’t have time to think about a dashboard to monitor their reputation. SEO firms must continue to help these clients get better traction and better visibility in the online space. A comprehensive review of their social standing and how they are engaging that community is huge.
Eric Enge: That means the opportunity, of course, for savvy businesses is to provide lots of signals and make more things available which will likely generate a positive buzz online.
![]() Stefan Weitz: Exactly. Imagine, especially as we begin to think about the world as this digital canvas, when we begin to implement things Project Leibniz to physical locations. If I am looking up the California Pizza Kitchen across the street from my house, traditionally we would look at that as a Lat and Long, we would look at it as a White Pages listing, or we may look at it as a webpage on its corporate site.
Stefan Weitz: Exactly. Imagine, especially as we begin to think about the world as this digital canvas, when we begin to implement things Project Leibniz to physical locations. If I am looking up the California Pizza Kitchen across the street from my house, traditionally we would look at that as a Lat and Long, we would look at it as a White Pages listing, or we may look at it as a webpage on its corporate site.
Now, because we think of it as an object, we understand that this particular CPK does have OpenTable or Urban Spoon reservations available, it has 48 seats in it, it has fifty Tweets in the last two days about how awesome the barbecue pizza was, it has n number of Facebook check-ins, and eight of your friends like it. All those pieces of data are being accrued back to that physical location. As a business owner, you need to make sure you have as many assets as you can that describe your location and allow people to push information back. This is huge from a search perspective.
The Future of Search
Eric Enge: As your final comments, would you offer some thoughts on the topic of where Bing is going with all this.
Stefan Weitz: It all comes back to the childhood vision many of us had which was the invisible and intelligent agents that could help us in many ways. I think back to the Apple Knowledge Navigator video I saw in 1986. A gentleman came into his office and interacted with a fully autonomous agent on a desk and asked that agent to do different things such as find the presentation he did last year, see if Kathy has availability next week, and check when he could make it to this conference.
The agent combined all the sources of information it had, everything it knew about that person and that person’s history. All the agent was doing was searching. Granted it was searching calendars, and history of documents, and where this particular location was, but those were all searches.
If you speak to someone like Jan Pederson, chief scientist at Bing, he will say the search box is the true universal interface. You should be able to ask it anything and we should be able to disambiguate what it is you are asking and marry up that with the right resources to resolve what it is you are trying to get done. That’s where I see it all going.
Eric Enge: You can learn when Joe asks a question he tends to use phrases one way, whereas Susie will use entirely different phrases. These may be based on her life experiences, where she lives, or what languages she uses. Disambiguating all that data and saying what you really want is this.
Stefan Weitz: Exactly. There is a user-specific model and you also think about things you are not necessarily asking anymore. I was in Sydney last week and had to get from Sydney to Canberra. That’s all well-documented in my calendar, where I have to be and when. The fact that I had no car reservation the agent could’ve alerted my agent to say Hey Weitz you are in Sydney on Thursday, you are going to be in Canberra on Friday, you have no way to get there, what’s going on?
The ability for the agent to process things that it knows about you and your current situation and actually proactively push things to you is another thing we see happening. It is not simply about the user asking, it is about being told.
Eric Enge: Or reminded as the case may be.
Stefan Weitz: Yes.
Eric Enge: It sounds as if it is an exciting time. I have maintained for a while that the rate of disruption in our world and industry has been accelerating for decades and the acceleration is only going to continue.
Stefan Weitz: Yes, I agree. People make mistakes about the linear acceleration model. Raymond Kurzweil and Michio Kaku talked about how people tend to underestimate how fast things will happen because they assume a linear progression of technology, and in our business, it is a logarithmic progression, it is not linear.
Eric Enge: Right, but it doesn’t always happen when you expect. For example, for five years we kept hearing that this will be the year of mobile, and it didn’t unfold until we had the iPhone to help it along.
Stefan Weitz: Yes.
Eric Enge: Other things happen in the meantime and change happens in unexpected directions and that is part of the fun.
Stefan Weitz: I know. It is such a blast.
Eric Enge: Thanks Stefan!